2024. 11. 2. 08:33ㆍDBMS/ORACLE Admin
Oracle은 데이터를 효과적으로 저장하고 관리하기 위한 데이터베이스 관리 시스템(DBMS, Database Management System) 이다. DBMS는 데이터베이스(Database)를 관리하는 프로그램으로, 데이터베이스는 데이터를 체계적으로 저장하는 공간을 의미한다. Oracle을 비롯한 DBMS의 구조와 원리를 이해하는 것은 중요하며 의사가 인체의 구조와 작동 원리를 이해해야 병을 진단하고 치료할 수 있는 것과 유사하다. Oracle을 잘 활용하고 관리하려면, 그 내부 구조와 작동 원리를 제대로 파악해야 효과적으로 운영할 수 있다.
컴퓨터는 기본적으로 작업을 수행하는 CPU(중앙처리장치), 작업 공간 역할을 하는 메모리(RAM), 그리고 데이터를 영구적으로 저장하는 하드 디스크(HDD)로 크게 나눌 수 있다. Oracle의 구조를 이해할 때도 주로 메모리와 저장 공간인 HDD에 중점을 두고 설명하게 된다.
Oracle은 데이터를 안전하게 저장하고, 필요 시 수정·검색·삭제할 수 있는 기능을 제공해 준다. 사용자 입장에서는 DBMS에 명령(SQL)을 전달해 원하는 데이터를 쉽게 얻을 수 있어 매우 편리한다. DBMS는 내부적으로 데이터가 저장된 Database를 관리하며, 실제 데이터 저장은 하드디스크에 이루어지지만, 데이터 검색·수정 등의 작업은 메모리에서 주로 수행된다. 이는 하드디스크보다 메모리의 속도가 훨씬 빠르기 때문이다.
Oracle 프로그램이 실행되면, 메모리와 저장 공간(HDD)을 사용하기 위해 작업 환경을 설정하게 된다. 이 작업의 효율성에 따라 성능이 달라지기 때문에, Oracle이 메모리를 어떻게 사용하는지, 저장소를 어떻게 관리하는지 등의 구조를 잘 이해하는 것이 중요하다.
Oracle Server의 전체 구조는 메모리(Instance)와 디스크(Database)로 나뉜다. 사용자가 Oracle Server에 접속하여 데이터를 조회하거나 관리하는 과정은 이 두 부분을 중심으로 이루어진다.
Oracle Server 구조
- 메모리(Instance): Oracle을 실행하면 메모리 상에 생성되는 구조로 데이터 처리와 사용자 요청을 효율적으로 수행할 수 있도록 메모리 자원을 관리하고, 데이터베이스 작업의 중심 역할을 한다.
- 디스크(Database): 데이터가 저장되는 디스크 구조로, 여러 파일로 구성된다.
- 데이터 파일(Data files): 실제 데이터가 저장되는 파일들로, 사용자가 요청하는 데이터가 여기 저장된다.
- 컨트롤 파일(Control files): 데이터베이스 전체의 구조와 상태 정보를 저장하는 파일들이다. 데이터베이스를 시작하고 관리하는 데 필수적인 정보가 담겨 있다.
- 리두 로그 파일(Redo log files): 장애 복구 시 사용되는 파일들로, 데이터 변경 이력을 저장하여 데이터 복구 시 활용된다.
이러한 구조를 이해하는 것은 Oracle을 효과적으로 사용하고 관리하는 데 매우 중요하다.
SGA는 실제 작업이 수행되는 공간으로, 데이터 버퍼와 SQL 실행 결과 등이 저장된다. 반면, 백그라운드 프로세스는 Oracle 서버가 원활히 운영될 수 있도록 지원한다.
Oracle 10g 버전부터는 ASMM(Automatic Shared Memory Management)이라는 기능이 추가되어 메모리 관리를 자동으로 최적화할 수 있게 되었고, 11g 버전에서는 AMM(Automatic Memory Management) 기능이 추가되어 관리가 더욱 간편해졌다.

Oracle 인스턴스(Instance)는 복잡한 구조를 가지고 있으며, 생성 과정 또한 단계적이다. Oracle 데이터베이스가 종료된 상태에서 관리자가 DB에 접속해 startup 명령으로 인스턴스를 시작한다고 가정하면 startup 명령을 수신한 첫 번째 Oracle 서버 프로세스는 초기화 파라미터 파일(pfile 또는 spfile)에 정의된 설정을 참고하여 운영 체제(OS)의 커널(Kernel)에 공유 메모리 할당 요청을 보낸다. 컴퓨터에서 하드웨어를 관리하는 OS 커널은 메모리(RAM) 작업이 필요할 때 그 사용을 허락하는 역할을 한다. 이때 커널은 자체 파라미터 파일(리눅스의 경우 /etc/sysctl.conf 파일, 유닉스 계열에서는 /etc/system 파일)을 확인하여 해당 설정에 따라 공유 메모리, 즉 SGA(System Global Area)를 할당한다. 이와 함께 세마포어 설정을 기반으로 다른 프로세스가 접근하지 못하도록 관리한다.
OS 커널이 Oracle이 요청하는 모든 메모리를 무조건 할당할 수는 없다. 서버의 총 RAM이 1GB인데 Oracle이 2GB의 메모리를 요청할 수 있기 때문이다. 따라서 커널은 설정 파일에 명시된 범위 내에서만 Oracle의 메모리 할당 요청을 승인하게 된다. 리눅스의 /etc/sysctl.conf 파일에 500MB로 설정되어 있다면, Oracle이 1GB를 요청하더라도 500MB만 허락된다.
또한, RAM을 물리적으로 추가해 전체 RAM 용량이 증가했다면, 커널의 설정 파일(/etc/sysctl.conf 등)도 변경해줘야 한다. 초기화 파라미터 파일은 SGA 영역을 생성할 때 참조되며, 집을 짓기 위한 설계도와 같은 역할을 한다.
SGA 생성은 최초 Oracle 서버 프로세스가 요청하지만, 일단 SGA가 생성되고 나면 OS 커널이 이를 관리한다. 초기 생성 요청을 했던 Oracle 서버 프로세스가 종료되더라도 SGA는 유지되며, 인스턴스가 완전히 종료되어야만 SGA가 메모리에서 해제된다.
OS 커널은 할당한 RAM 공간이 다른 프로그램에 의해 사용되지 않도록 관리한다. SGA는 모든 서버 프로세스가 동시에 사용하는 공유 메모리이므로, 다른 프로그램이 해당 메모리를 시도하지 못하도록 보호해야 한다. 이러한 보호를 위해 OS에서는 세마포어(Semaphore)와 여러 커널 파라미터를 사용하여 관리한다.
세마포어(Semaphore)는 특정 자원의 현재 사용 여부를 나타내는 신호로, 여러 프로그램이 공유 메모리를 함께 사용할 때 자원 충돌을 방지하는 데 쓰이다. Oracle의 SGA처럼 공유 메모리의 경우 여러 프로세스가 동시에 접근할 수 있는데, 이때 세마포어는 한 번에 하나의 프로세스만 특정 메모리 블록에 접근할 수 있도록 관리한다. 한 프로세스가 메모리를 사용 중이라면 다른 프로세스는 그 자원에 접근할 수 없게하여 메모리 충돌을 방지하고 데이터 무결성을 유지할 수 있다.
또, RAM은 모든 프로그램이 동시에 사용하는 공간이므로, 하나의 메모리 블록에 여러 프로세스가 동시에 접근하면 충돌 문제가 발생할 하여 메모리 오류나 운영체제의 블루 스크린 현상이 나타날 수 있다.
만약 세마포어가 '사용 중(set)' 상태라면 다른 프로세스는 자원을 사용할 수 없으므로 대기한다. 자원이 해제되어 '미사용(unset)' 상태가 되면 프로세스가 세마포어를 '사용 중'으로 설정하고 자원을 사용할 수 있다. 세마포어는 이렇게 자원이 사용 중인지 아닌지를 표시하며, 보통 단일 개가 아닌 세트로 묶여 여러 개로 사용된다.
■ Oracle에서 세마포어와 관련된 주요 커널 파라미터
각 파라미터는 Unix 계열 운영체제에 적용된다. Unix OS별로 권장 수치가 다를 수 있으므로 설치 매뉴얼에서 Oracle 버전에 맞는 권장 값을 확인하는 것이 좋다.
- SEMMSL: 하나의 세마포어 세트당 최대 세마포어 개수를 정의한다. 여러 프로세스가 동시에 세마포어를 사용할 때 개별 세마포어를 묶어 세트로 사용하므로, 세마포어의 수가 증가할 수 있다. Oracle 설치 및 운영 시 권장 값은 PROCESSES 변수의 최대값에 10을 더한 값이며, 기본값은 최소 100 이상이다. Oracle 11g의 경우 PROCESSES 기본값은 150이다.
- SEMMNI: 시스템 전체에서 설정할 수 있는 세마포어 세트의 최대 개수를 의미하며, Oracle에서 권장하는 값은 최소 10 이상이다.
- SEMMNS: 시스템 전체에서 사용 가능한 세마포어의 최대 개수를 의미한다. 이 값은 이론적으로 SEMMSL과 SEMMNI의 곱과 같거나 커야 한다 (SEMMNS >= SEMMSL * SEMMNI).
- SEMOPM: 1회의 시스템 호출에서 처리할 수 있는 최대 세마포어 개수를 정의한다. 하나의 시스템 호출을 통해 여러 개의 세마포어를 지원할 수 있으며, 세마포어 세트에서 사용 가능한 최대값은 SEMMSL로 설정된다. 보통 SEMOPM은 SEMMSL과 동일하게 설정하는 것이 좋다.
세마포어 설정 확인 방법
다음 명령어로 현재 시스템에 설정된 세마포어 값을 확인할 수 있다:

- max number of arrays (SEMMNI): 세마포어 세트의 최대 개수를 의미하며, 현재 설정은 128이다. 이 값은 시스템에서 동시에 사용할 수 있는 세마포어 세트의 최대 수를 의미한다.
- max semaphores per array (SEMMSL): 세마포어 세트당 포함할 수 있는 최대 세마포어의 개수를 의미한다. 현재 값은 250으로, 각 세마포어 세트가 가질 수 있는 최대 세마포어 수이다.
- max semaphores system wide (SEMMNS): 시스템 전체에서 사용할 수 있는 세마포어의 총 개수를 나타내며, 현재 설정은 32000이다. 이 값은 SEMMSL과 SEMMNI의 곱보다 크거나 같아야 한다.
- max ops per semop call (SEMOPM): 한 번의 시스템 호출로 처리할 수 있는 최대 세마포어 개수를 의미하며, 현재 설정은 100이다. 보통 SEMMSL과 같은 값으로 설정하는 것이 권장된다.
- semaphore max value: 각 세마포어의 최대값을 나타내며, 현재 32767로 설정되어 있다. 이는 각 세마포어가 가질 수 있는 최대 허용 값이다.
Oracle에서 사용하는 주요 세마포어 외에도, 공유 메모리(SGA) 관련 여러 커널 파라미터가 있다. 이 파라미터들은 운영체제가 Oracle의 메모리와 자원 관리를 효율적으로 수행하도록 돕는 역할을 한다.
리눅스 환경에서는 이러한 커널 파라미터 설정이 /etc/sysctl.conf 파일에, Solaris와 같은 유닉스 시스템에서는 /etc/system 파일에 위치한다. Oracle 설치 시 해당 파일에서 커널 파라미터를 설정하고, 시스템 리소스가 Oracle 데이터베이스를 안정적으로 지원할 수 있도록 최적화된 값을 적용하는 것이 중요하다.
SHMMAX는 공유 메모리 세그먼트의 최대 크기를 정의하는 커널 파라미터로, 바이트 단위로 설정된다. Oracle의 SGA(System Global Area)는 공유 메모리로 구성되며 여러 서버 프로세스가 동시에 접근하여 사용하게 된다.
SHMMAX의 역할
많은 프로그램이 공유 메모리를 사용하는 상황에서, 운영체제가 여러 번 작은 크기의 메모리를 할당하기보다는 큰 덩어리의 메모리를 한 번에 할당하는 것이 효율적이다. 이 큰 덩어리를 세그먼트라고 부르며, SHMMAX는 이 세그먼트의 최대 크기를 지정한다.
- 예시: 만약 Oracle이 10MB의 RAM을 필요로 하는데, SHMMAX가 2MB로 설정되어 있다면, Oracle은 10MB의 메모리를 5개의 세그먼트로 나누어 사용해야 한다. 이는 한 테이블에 모두 앉을 수 없는 단체 손님이 여러 테이블에 분산되는 상황과 비슷하여, 메모리 접근의 효율이 떨어질 수 있다.
- 주의 사항: 설정을 너무 크게 해도 문제가 발생할 수 있다. 1명씩 앉을 수 있는 큰 테이블만 마련했는데, 실제로 손님이 소규모로 온다면, 테이블의 많은 부분이 낭비되는 상황이 발생할 수 있다. 마찬가지로, SHMMAX가 필요 이상으로 크면 메모리 낭비가 발생할 수 있고, SGA 크기 설정이 잘못되어 Oracle이 정상적으로 동작하지 않을 수 있다.
오류 메시지
SHMMAX가 올바르게 설정되지 않으면, Oracle이 메모리 할당에 실패하여 다음과 같은 오류 메시지를 출력할 수 있다:
- "ORA-27102: out of memory"
Oracle에서 SGA를 사용하기 위해 SHMMAX 값이 너무 작게 설정되어 있다면, Oracle 데이터베이스가 정상적으로 메모리를 할당하지 못하고 오류가 발생할 수 있다. , SHMMAX 값이 작을 때 다음과 같은 오류 메시지를 볼 수 있다:
- ORA-12547: TNS: lost contact
- ORA-27123: unable to attach to shared memory segment
SHMMAX 값 확인 및 설정 방법
현재 시스템의 SHMMAX 값은 다음 명령으로 확인할 수 있다:

SHMMAX 값은 바이트 단위이며, Oracle SGA를 지원하기에 충분한 값으로 설정해야 한다. 일반적으로 SHMMAX 값을 2GB로 설정하는 것이 권장된다.

SHMMAX 값 변경 방법
서버를 재부팅하지 않고 SHMMAX 값을 즉시 변경하려면 /proc 파일 시스템에 값을 직접 반영한다:
(root@localhost ~)# echo "2147483648" > /proc/sys/kernel/shmmax
(root@localhost ~)# cat /proc/sys/kernel/shmmax
2147483648 # 변경 후 값, 2GB
이 변경 사항은 서버 재부팅 후에도 유지하려면 /etc/sysctl.conf 파일에 추가한다:
# /etc/sysctl.conf 파일 열기
(root@localhost ~)# nano /etc/sysctl.conf
# shmmax 설정 추가
kernel.shmmax = 2147483648
# 변경 사항 적용
(root@localhost ~)# sysctl -p
SHMMNI, SHMALL, SHMMIN 설명
1. SHMMNI
- 설명: SHMMNI 매개변수는 시스템에서 생성할 수 있는 공유 메모리 세그먼트의 최대 개수를 설정한다.
- 기본값: 일반적으로 4096이다.
- 사용 예시: Oracle이 사용 가능한 전체 RAM의 크기가 1GB이고, SHMMAX가 2GB일 경우 Oracle은 총 5개의 세그먼트를 만들어 SGA로 사용할 수 있다.
- 설정 확인 방법:
cat /proc/sys/kernel/shmmni2. SHMALL
- 설명: SHMALL 변수는 시스템에서 특정 시점에 사용 가능한 공유 메모리의 최대 크기를 페이지 단위로 정의한다.
- 권장값: ceil(SHMMAX / PAGE_SIZE)보다 큰 값을 사용해야 한다.
- 기본값: 2097152 bytes (2GB).
- 페이지 크기: Red Hat Linux에서는 보통 4096 바이트(4KB)이다.
- 설정 확인 방법:
cat /proc/sys/kernel/shmall3. SHMMIN
- 설명: SHMMIN은 단일 공유 메모리 세그먼트의 최소 크기(바이트)를 의미한다. 이 값은 공유 메모리 세그먼트를 생성할 때, 각 세그먼트가 갖추어야 할 최소 크기를 정의한다.
SHMSEG
SHMSEG 매개변수
- 설명: SHMSEG는 각 프로세스가 사용할 수 있는 공유 메모리 세그먼트의 최대 개수를 설정하며 SHMMNI와는 다르게, 시스템 전체가 아닌 개별 프로세스가 가질 수 있는 공유 메모리 세그먼트의 제한이다.
- 사용 예시: 특정 프로세스가 여러 작업을 동시에 수행하기 위해 여러 메모리 세그먼트를 요청할 때, 이 값을 넘어설 수 없다.
- 주의사항: SHMSEG의 설정값은 해당 프로세스가 메모리를 요청할 때의 최대 허용치일 뿐, 매번 이 값만큼 메모리를 사용하는 것은 아니다.
메모리 할당 방식 (Oracle SGA 할당 방법)
Oracle이 SGA로 사용할 공유 메모리를 할당할 때는 다음 세 가지 방법 중 하나를 통해 할당할 수 있다:
- 단일 세그먼트 할당: 물리적 메모리가 충분한 경우, 하나의 큰 세그먼트에 전체 SGA가 할당된다.
- 연속된 여러 세그먼트 할당: 단일 세그먼트로는 할당이 어려운 경우, 연속된 여러 세그먼트로 나눠 할당된다.
- 비연속 여러 세그먼트 할당: 연속된 세그먼트로도 할당이 어려울 경우, 비연속된 여러 세그먼트로 분산해 할당할 수 있다.
이때, 중요한 부분은 SGA의 특정 핵심 데이터 구조가 반드시 첫 번째 세그먼트에 포함되어야 한다는 것이다.
Oracle SGA 메모리 할당 방식 요약
Oracle SGA 메모리를 할당하는 데는 가장 성능이 좋은 연속 메모리 할당 방식부터, 상황에 따라 사용할 수밖에 없는 비연속 메모리 할당 방식까지 총 세 가지 방법이 있다.
- 연속 메모리 할당 (최적의 방법)
- SGA를 하나의 연속된 메모리 공간에 할당한다.
- 예: 회식 자리에 모든 사람이 한 테이블에 모여 앉는 것과 같다. 가장 효율적이고 성능이 좋다.
- 연결된 여러 세그먼트에 할당 (차선의 방법)
- 하나의 연속된 메모리 공간을 할당하지 못할 때, 연결된 여러 메모리 세그먼트로 할당한다.
- 예: 같은 회식 자리에서 여러 테이블을 이어 붙여 앉는 경우이다. 약간의 성능 저하가 있을 수 있지만, 여전히 관리 가능하고 효과적이다.
- 비연속 여러 세그먼트에 할당 (비추천)
- 연속적인 메모리 공간이 없을 때, 비연속적으로 떨어진 여러 세그먼트에 할당한다.
- 예: 사람들이 떨어진 테이블에 나뉘어 앉는 상황이다. 성능이 떨어지며 작업 효율이 낮아진다.
메모리 단편화 해결 방안
만약 메모리가 세 번째 방식처럼 비연속 세그먼트에 할당될 경우, 메모리가 단편화되어 성능 저하가 발생한다. 이러한 상황에서는 메모리를 정리하여, Oracle이 다시 연속적인 메모리 공간을 확보할 수 있도록 해야 한다.
■ SGA의 주요 구성 요소
Oracle 프로그램이 실행되면 Oracle 프로세스는 운영 체제의 커널에게 공유 메모리를 요청하여 SGA를 생성한다. 이 과정에서 파라미터 파일과 여러 설정 정보를 바탕으로 SGA를 구성하는 다양한 요소들이 생성된다.
SGA의 역할과 중요성
SGA는 Oracle에서 대부분의 작업이 수행되는 핵심 공간으로, 이를 제대로 이해하고 관리하면 Oracle 성능을 최적화할 수 있다. 반면에, SGA를 잘못 설정하거나 관리하면 Oracle의 성능이 저하될 위험이 있다.
Database Buffer Cache
Database Buffer Cache는 Oracle SGA의 가장 중요한 구성 요소 중 하나이다. 데이터의 조회와 변경 작업이 실제로 이루어지는 공간으로, 모든 데이터 조회와 변경은 Database Buffer Cache에서 수행된다.
역할과 동작 방식
- 데이터 처리 속도 향상: 사용자가 조회 또는 변경하고자 하는 데이터는 Database Buffer Cache에 저장되어야 작업이 가능하다. 만약 해당 데이터가 Cache에 없다면, 하드디스크의 데이터 파일에서 필요한 블록을 복사하여 Database Buffer Cache에 가져온다. 이 방식은 메모리에서 작업을 수행하므로 작업 속도가 빠르고, 디스크 작업보다 효율적이다.
- 공유 및 다중 사용자 환경: Database Buffer Cache는 여러 사용자가 공유하여 사용할 수 있고 사용자들이 동일한 데이터를 사용할 수 있으며, 이를 통해 다중 사용자 환경에서 전체적인 작업 속도가 빨라진다.
데이터 처리 방식
- 조회 및 변경 작업: SELECT 문이나 DML 문장(INSERT, UPDATE, DELETE 등)을 통해 데이터를 조회하거나 변경할 때 해당 데이터가 Cache에 존재하지 않으면, 디스크의 데이터 파일에서 필요한 블록을 복사하여 Cache로 가져온다. 이후, 해당 블록에서 작업이 수행된다.
데이터 블록 관리와 상태
Database Buffer Cache의 블록은 여러 사용자가 동시에 사용하거나 접근할 수 있기 때문에 데이터 충돌이나 오류(예: kernel panic)를 방지해야 한다. 이를 위해 Oracle은 Cache 블록을 3가지 상태로 관리하며, 각 상태별로 리스트를 통해 데이터 블록을 추적한다.
Database Buffer Cache 블록 상태
Oracle의 Database Buffer Cache는 다양한 상태의 Buffer 블록으로 구성된다. 이 블록들은 메모리 공간에서 다양한 작업을 효율적으로 수행할 수 있도록 세 가지 상태로 관리된다.
1. Pinned Buffer
- 정의: 현재 다른 사용자가 사용하고 있는 Buffer 블록이다.
- 제한: A 사용자는 Pinned 상태의 Buffer에 접근할 수 없다.
2. Dirty Buffer
- 정의: 사용자가 변경한 데이터가 담긴 Buffer로, 아직 디스크의 데이터 파일에 저장되지 않은 상태이다.
- 제한: Dirty Buffer는 다른 사용자가 덮어쓰면 안 되기 때문에, A 사용자는 이 Buffer를 사용할 수 없다.
3. Free Buffer
- 정의: 사용되지 않거나(Unused) Dirty Buffer였다가 데이터 파일에 저장이 완료된 후 재사용 가능한 상태의 블록이다.
LRU(Least Recently Used) List와 Buffer 관리
Database Buffer Cache에는 많은 수의 Buffer Block이 존재하며, Oracle은 이들의 상태를 관리하기 위해 LRU(Least Recently Used) List를 사용한다. 이 리스트는 메모리 공간의 한계를 고려하여 효율적인 메모리 사용을 돕는 관리 알고리즘을 사용한다.
- LRU 알고리즘: 자주 사용되지 않는 블록부터 순서대로 덮어쓰는 방식으로 메모리를 관리하여 Cache에서 더 이상 사용하지 않는 데이터는 삭제하고, 새로운 데이터를 위한 공간을 확보할 수 있다.
매장 진열의 LRU 알고리즘 적용
- 상황 설정: 매장의 진열대에는 최대 18개의 제품을 놓을 수 있다. 현재 모든 자리가 채워져 있어, 새로운 제품을 추가하려면 기존 제품 중 하나를 빼야 한다.
- 기존 제품 교체: 주인은 손님들이 찾지 않는 제품, 즉 잘 판매되지 않는 제품을 우선적으로 빼고 새 제품을 진열할 것이다. 이렇게 자주 찾지 않는 제품을 제거해 자리를 비우는 방식이 LRU 알고리즘의 핵심이다.
Oracle에서의 LRU 적용
Oracle의 SGA(Shared Global Area) 내에는 여러 구성 요소가 있으며, 그 중 Shared Pool과 Database Buffer Cache가 LRU 알고리즘을 적용해 메모리 공간을 효율적으로 관리한다.
- Database Buffer Cache: 자주 사용되지 않는 블록부터 순차적으로 덮어쓰거나 제거하여 새로운 데이터를 위한 공간을 확보한다.
Database Buffer Cache는 Oracle에서 자주 조회되거나 변경된 데이터를 빠르게 접근하기 위해 사용된다. 하지만 이 공간은 제한적이어서 모든 데이터 블록을 영구적으로 저장할 수 없기 때문에 LRU(Least Recently Used) 알고리즘을 활용해 효율적으로 관리한다.
LRU 알고리즘과 Database Buffer Cache 관리 방식
- 기존 블록 덮어쓰기: 만약 사용자가 요청한 데이터 블록을 Database Buffer Cache로 가져와야 하지만, 저장할 여유 공간이 없다면 기존 블록을 덮어쓰는 방식으로 공간을 확보해야 한다.
- 안전한 블록 선택: 덮어쓸 블록을 선택할 때, 현재 사용 중인 블록을 덮어쓰면 안 되기 때문에 LRU List를 사용한다.
- LRU List는 데이터 블록이 얼마나 자주 사용되었는지를 기반으로 블록의 순서를 유지하며, 오랫동안 사용되지 않았거나 이미 작업이 완료된 블록부터 우선적으로 덮어쓴다.
- 이로 인해 다른 사용자가 현재 작업 중인 데이터 블록을 보호할 수 있고, 작업의 안정성이 유지된다.
Oracle의 Database Buffer Cache에서 효율적인 메모리 관리와 스캔을 위해 LRU 리스트와 LRUW 리스트라는 두 가지 리스트로 나누어 관리한다. 이 리스트들을 합쳐 Working Data Set 또는 Working Set이라고 부른다.
LRU List
- 메인 리스트:
- 사용된 Buffer들이 포함되어 있다.
- Hot 영역과 Cold 영역으로 나뉘며, 자주 사용된 블록은 Hot 영역에, 오래된 블록은 Cold 영역에 위치한다.
- 보조 리스트 (Free List):
- 미사용된 Buffer들이나, DBWR(Database Writer)에 의해 기록 완료된 Buffer들을 보관한다.
- 이 리스트에 있는 블록들은 다시 사용할 수 있는 상태로, 필요 시 다른 데이터로 덮어쓰기 가능한다.
LRUW List
- 메인 리스트 (Dirty List):
- 변경된 Buffer들이 포함된 리스트로, 이를 Dirty List라고도 부른다.
- 여기에는 변경된 데이터가 아직 디스크에 기록되지 않은 상태의 Buffer들이 포함된다.
- 보조 리스트:
- 현재 DBWR에 의해 기록 중인 Buffer들이 포함된 리스트이다.
- 기록 중인 데이터는 다른 프로세스가 사용하지 못하도록 보호되며, 기록 완료 시 Free List로 이동한다.
Oracle Database에서 사용자가 데이터 파일의 데이터를 DB Buffer Cache로 가져와야 할 경우, 데이터 파일에서 블록을 복사하기 전에 DB Buffer Cache에 Free 상태의 Buffer를 확보해야 한다. 이를 위해 다음과 같은 과정이 이루어진다.
- Free Buffer 확보:
- 우선, LRU 리스트의 보조 리스트에서 Free 상태의 Buffer를 찾는다.
- 만약 보조 리스트의 모든 Buffer가 이미 사용 중이라면, 메인 리스트의 Cold 영역에서 Free 상태의 Buffer를 다시 검색한다.
- DBWR 호출 조건:
- Free Buffer를 찾다가 설정된 기준 (Oracle 10g 기준으로 40%)만큼을 찾지 못하게 되면, 스캔을 멈추고 DBWR(Database Writer) 프로세스에게 Dirty Buffer를 내려 쓰도록 요청하게 된다.
- DBWR는 DB Buffer Cache에 있는 변경된 데이터를 데이터 파일에 저장하는 백그라운드 프로세스로, 이 작업을 통해 더 많은 Free Buffer를 확보한다.
- Dirty Buffer의 상태 변경:
- Dirty Buffer가 데이터 파일로 내려 쓰여 저장이 완료되면, 해당 버퍼의 상태는 Free Buffer로 변경된다.
- 이 Free Buffer는 다시 LRU 리스트의 보조 리스트에 추가된다.
- 데이터 파일에서 데이터 복사:
- 사용자는 확보한 Free Block을 사용하여 필요한 블록을 데이터 파일에서 Database Buffer Cache로 복사할 수 있게 된다.
- 참고로, 데이터 파일에서 필요한 블록을 DB Buffer Cache로 복사해 오는 작업은 Server Process에 의해 수행된다.
처음 인스턴스가 시작될 때는 모든 Buffer가 LRU 리스트의 보조 리스트에서 관리된다.
DB Buffer Cache를 다수의 사용자들이 동시에 사용하면 LRU List와 같은 리스트에 접근해야 하므로 경합이 발생할 수 있다. , 100명의 사용자가 각각 다른 데이터 블록에 접근하려고 하면 제한된 수의 Buffer Cache 블록을 사용할 수 있기 때문에 충돌이 발생할 수 있다. 특히, 동시에 여러 Server Process가 Free Block을 찾으려 할 경우 대기 시간이 늘어나고 성능 저하가 발생할 수 있다.
이를 방지하기 위해 Oracle은 DB Buffer Cache를 보다 효율적으로 관리하는 방법으로 여러 개의 구역으로 분할하여 관리한다. 이러한 구역들은 Working Data Set이라는 그룹으로 나누어져, 여러 사용자가 동시에 Free Buffer를 더 빠르게 찾을 수 있게 한다.
그럼에도 불구하고, 매우 많은 사용자가 집중적으로 DB Buffer Cache에 접근하게 되면 여전히 대기 현상이 발생할 수 있으며, 이는 작업 속도 저하로 이어질 수 있다. Oracle의 Buffer Cache는 이러한 문제를 완화하기 위해 다양한 최적화 기법을 적용하지만, 최적의 성능을 유지하려면 메모리 자원의 충분한 할당과 시스템의 적절한 튜닝이 필요한다.
Latch는 제한된 자원을 여러 프로세스가 동시에 사용할 때 순서를 관리하는 중요한 역할을 한다. 은행의 번호표처럼 각 프로세스가 자원을 사용하는 순서를 정해주는 기능을 하며, 모든 메모리 자원에는 각각의 Latch가 존재한다. Latch는 메모리 자원의 충돌을 방지하고, 특정 자원에 대해 순서를 지키면서 접근할 수 있도록 도와준다.
Oracle의 Redo Log Buffer에 변경 사항을 기록할 때는 Redo Copy Latch와 Redo Allocation Latch를 차례로 확보한 후에야 변경 내용을 기록할 수 있다. 이는 공유 메모리를 여러 프로세스가 사용하기 때문에 순서를 관리해 자원 접근의 충돌을 방지하기 위함이다.
모든 프로세스는 특정 메모리 자원에 접근하기 위해 반드시 그 메모리의 Latch를 확보해야 한다. 따라서 Oracle에서 Latch와 Lock 개념은 자원 관리 및 튜닝에서 자주 언급되는 중요한 요소로, 특히 Database Buffer Cache와 같은 자원은 접근 순서가 잘 관리되어야 성능 저하를 방지할 수 있다.
결론적으로, 사용자가 조회하거나 변경하려는 데이터는 Database Buffer Cache에 반드시 존재해야 하며, 이곳에서 메모리 충돌을 방지하기 위해 Latch가 중요한 역할을 수행한다.
Redo Log Buffer
Oracle의 Redo Log Buffer는 데이터 변경 사항이 발생할 때 이를 기록하는 메모리 공간이다. 데이터 정의 언어(DDL), 데이터 조작 언어(DML), 트랜잭션 제어 언어(TCL) 명령어로 인한 데이터 변경이 있을 때마다 변경 내용을 기록하여, 예기치 않은 장애가 발생할 경우 이를 통해 복구할 수 있도록 지원한다.
Redo Log는 금융 장부처럼 모든 변경 기록을 남기며, 문제가 생겼을 때 이를 바탕으로 데이터 복원을 진행한다. Redo Log Buffer는 이러한 변경 사항을 저장하는 메모리 영역이며, Redo Log File은 이를 디스크에 저장해주는 파일이다.
중요한 점은 변경 사항에 대한 기록만 Redo Log에 저장된다는 것이다. SELECT와 같은 단순 조회 명령어는 Redo Log에 기록되지 않다. 또한, 모든 변경 사항이 Redo Log에 저장되는 것도 아니다. Direct Load 방식(SQL Loader, INSERT /*+APPEND*/)을 사용하거나 NOLOGGING 옵션으로 테이블이나 인덱스를 생성하면, 해당 작업은 Redo Log에 기록되지 않다. 다만, NOLOGGING 옵션이 적용된 테이블에서도 일반적인 INSERT, UPDATE, DELETE 같은 DML 작업은 Redo Log에 기록된다.
시스템에 장애가 발생할 경우 Redo Log는 복구의 핵심 자료가 되므로, 반드시 잘 관리하고 이해해야 한다.

Shared Pool
Shared Pool은 Oracle SGA의 주요 구성 요소 중 하나로, 여러 사용자와 프로세스가 함께 사용할 수 있는 메모리 공간이다. 이 영역은 다양한 데이터를 공유함으로써 성능을 개선하고 메모리 사용을 최적화하는 역할을 한다. Shared Pool은 다음과 같은 여러 공간으로 나누어진다:
- Library Cache:
- Soft Parse할 때 사용되는 공간으로, 이미 실행된 SQL 문장과 PL/SQL 문장의 Parse Codes, 실행 계획 등이 저장된다.
- LRU 알고리즘으로 관리되어, 가장 최근에 사용된 SQL 문장이 우선적으로 캐시된다. Soft Parse와 Hard Parse에 대한 개념은 SQL 처리 과정에서 더 자세히 설명될 예정이다.
- Data Dictionary Cache (Row Cache):
- 구문 분석이나 옵티마이저가 실행 계획을 수립할 때 사용되는 주요 Dictionary 정보가 Row 단위로 캐시된다.
- 이 공간 역시 LRU 알고리즘을 통해 관리되며, 데이터베이스의 메타데이터 정보가 포함된다.
- Server Result Cache (11g부터 추가):
- 쿼리 결과를 캐싱하여 반복되는 SQL 쿼리의 성능을 향상시키는 기능이다.
- SQL 문장이 실행된 후 그 결과가 이 캐시에 저장되어 다음 번 동일한 쿼리가 실행될 때, 디스크 I/O를 줄이고 성능을 높이다.
Server Result Cache
Server Result Cache는 쿼리의 결과값을 캐시해두는 공간으로, 동일한 쿼리 실행 시 DB Buffer Cache에 여러 번 접근하지 않고 빠르게 결과를 반환할 수 있게 한다. 11g 이전에는 이러한 캐시가 없었기 때문에 SELECT 문을 실행할 때마다 DB Buffer Cache에서 데이터를 인출해 사용자에게 반환하는 과정에서 대기 시간이 발생하고 성능 저하가 나타날 수 있었다.
Server Result Cache가 추가되면서 반복되는 쿼리에 대해 캐시된 결과를 활용해 성능을 향상시키는 기능을 제공하게 되었다.
Server Result Cache는 Oracle 11g부터 도입된 기능으로, SELECT 쿼리 결과를 Shared Pool 내의 Server Result Cache에 저장해 두었다가 동일한 SELECT 문이 재실행되면 DB Buffer Cache를 거치지 않고 바로 결과를 반환하는 방식이다.
이 방식은 DB Buffer Cache에 대한 불필요한 접근을 줄여 성능을 개선할 수 있으나, 실무에서 적용할 때는 충분한 테스트를 통해 적합성을 확인하는 것이 중요하다. 테스트는 DB 서버 환경과 사용량을 반영해야, 실무에서 실제 성능 개선 효과를 얻을 수 있다.
Server Result Cache 활성화 및 사용 방법
Oracle 11g부터 도입된 Server Result Cache 기능은 기본적으로 사용 안 함 상태로 설정되어 있다. 이 기능을 사용하려면 SELECT 문에서 힌트 구문을 추가하여 설정하거나, 매번 힌트를 사용하지 않으려면 시스템 파라미터인 RESULT_CACHE_MODE를 FORCE로 변경하여 모든 SELECT 문에서 Result Cache를 자동으로 사용하게 할 수 있다.
- 힌트 사용: SELECT 문에 /*+ result_cache */ 힌트를 추가해 Result Cache를 사용하도록 지정할 수 있다.
- 파라미터 변경: RESULT_CACHE_MODE를 FORCE로 설정하면, 힌트를 사용하지 않아도 자동으로 Result Cache를 사용한다. 이 파라미터의 기본값은 MANUAL이며, 이는 힌트를 사용할 때만 Result Cache를 활성화하도록 설정된 상태이다.



-scott.rtest 테이블에서 Result Cache를 사용했을 때와 사용하지 않았을 때의 성능을 비교하는 테스트

- Result Cache 미사용 시

- Result Cache 사용 시


- Result Cache 효과가 미미한 경우: 데이터가 매우 큰 경우 Result Cache는 성능 향상에 큰 영향을 미치지 않을 수 있다.
- DB Buffer Cache가 이미 충분히 최적화된 경우, 데이터를 별도로 캐시하지 않고 직접 읽어도 성능이 유사할 수 있다.
RESULT_CACHE_MODE 설정 변경 Result Cache 힌트를 사용하지 않고 자동으로 적용하도록 시스템 설정을 변경

Server Result Cache 기능의 역할 및 주의사항
이 기능은 여러 사용자가 동시에 Database Buffer Cache를 액세스하면서 발생하는 성능 저하를 개선하기 위해 도입되었다. 특히, DBWR이 기록 중인 데이터 블록에 접근해야 하는 경우, 기존에는 DBWR의 기록이 완료될 때까지 대기해야 했지만, Server Result Cache 기능을 활용하면 대기하지 않고 즉시 캐시된 결과를 조회할 수 있다.
그러나, 주의해야 할 몇 가지 사항이 있다:
- Result Cache에 결과가 없으면 Database Buffer Cache로 이동하여 데이터를 조회해야 하므로 오히려 시간이 더 걸릴 수 있다.
- 데이터의 일관성: Database Buffer Cache의 값이 변경되면 Result Cache의 데이터도 갱신되어야 한다.
Server Result Cache의 내부 구조
- SQL Query Result Cache: SQL 문장의 결과를 저장한다.
- PL/SQL Function Result Cache: PL/SQL 함수의 수행 결과를 저장한다.
Reserved Pool
이 공간은 Shared Pool에서 5KB 이상 크기의 객체가 로드될 때 사용된다. 주로 대용량 Java 객체나 PL/SQL, SQL 객체가 적재되어야 하는 상황에 사용되며, Shared Pool 공간이 부족할 때 이를 보완하기 위한 공간이다.
Oracle에서는 Shared Pool Reserved 공간이 내부적으로 자동 설정되어 필요한 경우 사용된다. 그러나 관리자가 공간 크기를 직접 설정하려면 파라미터 파일에서 SHARED_POOL_RESERVED_SIZE 파라미터로 용량을 설정할 수 있다. 이 공간의 기본 크기는 인스턴스가 시작될 때 Shared Pool Size의 5%로 설정되며, 최대값은 Shared Pool Size의 50%이다.
이 공간이 부족한지 충분한지 확인하려면 V$SHARED_POOL_RESERVED 뷰를 조회하면 된다. 여기서 REQUEST_FAILURES 값이 증가하면 공간이 부족하다는 의미이므로 용량을 늘려야 한다. 반면, REQUEST_MISSES 값이 0이거나 증가하지 않으면 공간이 부족하지 않음을 나타낸다.
Shared Pool의 전체 크기는 shared_pool_size 파라미터로 설정할 수 있지만, Library Cache나 Dictionary Cache의 크기는 각각 별도로 관리할 수 없다. shared_pool_size는 동적 파라미터로, DB를 종료하지 않고도 사이즈를 변경할 수 있다 (이 기능은 Oracle 9i 버전부터 가능하게 되었다).
ALTER SYSTEM SET shared_pool_size=100M
Shared Pool의 크기를 조정
주의할 점은 Oracle이 메모리를 특정 단위로 할당하고 해지한다는 점이다.
Large Pool
Large Pool은 필수 구성 요소는 아니지만 복잡한 기능을 사용할 때 도움이 되는 선택적 구성 요소이다. Large Pool을 사용하는 주요 사례는 다음과 같다:
- Shared Server 모드: Oracle Server가 Shared Server 모드로 운영되는 경우 UGA(User Global Area)가 Large Pool에 할당된다.
- 병렬 실행(Parallel Execution): 병렬 처리 작업 시 각 프로세스 간에 메시지 버퍼가 Large Pool에 생성된다.
- RMAN 백업 및 복구: RMAN을 사용하여 백업이나 복구 작업을 수행할 때, RMAN에서 사용하는 I/O용 버퍼가 이곳에 생성된다.
Large Pool은 Shared Pool과 달리 LRU(Least Recently Used) 알고리즘으로 관리되지 않는다.
JAVA POOL
Java Pool은 SGA의 필수 공간은 아니며, Java 관련 코드나 Java Virtual Machine (JVM) 관련 데이터를 저장하기 위해 생성되는 선택적인 공간이다.
STREAMS POOL
Streams Pool은 Oracle 10g 이상 버전부터 추가된 SGA 구성 요소로, Streams 기능을 사용할 경우에만 사용된다. 관리자가 설정하지 않으면 기본값은 0으로 설정되며, Streams 기능을 활성화하면 Oracle Streams가 동적으로 크기를 증가시킨다.
FIXED SGA
Fixed SGA는 Oracle이 내부적으로 사용하기 위해 생성하는 공간이다. 이 공간에는 주로 백그라운드 프로세스들이 필요한 데이터베이스의 전반적인 공유 정보나 각 프로세스 간에 공유해야 하는 Lock 정보와 같은 내용들이 저장된다. 이 공간의 크기는 Oracle이 시작될 때 자동으로 설정되며, 사용자나 관리자가 임의로 변경할 수 없다.
Dynamic SGA 기능
Oracle 프로세스는 커널에게 RAM의 일부를 SGA로 사용할 수 있도록 공간을 할당받은 후, 파라미터 파일에 적혀 있는 값을 참조하여 SGA의 세부적인 구조를 만든다. SGA의 내부 구성 요소는 매우 복잡하며, 각 구성 요소는 성능에 매우 중요한 영향을 미치기 때문에 정확하게 설정해야 한다.
Oracle 8i 버전까지는 이러한 구성 요소의 크기를 변경하기 위해 인스턴스를 중단한 후 재시작해야 했다. 이 방식은 Static SGA로 운영되었으며, 변경 사항이 반영되기 위해서는 반드시 인스턴스의 재시작이 필요했다.
이와 달리, Dynamic SGA 기능은 Oracle 9i 버전부터 도입되어 인스턴스를 재시작하지 않고도 SGA 구성 요소의 크기를 동적으로 조정할 수 있게 되었다. 이는 데이터베이스의 성능을 최적화하고, 메모리 자원의 활용을 더욱 효율적으로 할 수 있게 한다.
사용자들이 요청한 SELECT 문장의 속도가 너무 느릴 경우 일반적으로 Database Buffer Cache라는 구성 요소의 효율성을 점검하고, 용량이 부족하다고 판단되면 사이즈를 증가시키는 조치를 취한다. 그러나 문제는 이러한 구성 요소의 사이즈를 증가시키기 위해 Oracle 8i 이전 버전에서는 데이터베이스를 재시작하지 않으면 기존의 값으로 계속 운영된다는 것이다. 이는 모든 서비스가 중단되는 것을 의미하므로, 특히 느린 서비스가 갑자기 모든 고객의 요청을 중단시킨다면 고객들의 불만이 클 수 있다.
하지만 Oracle 9i부터 Dynamic SGA 기능이 도입되어 이러한 문제가 많이 개선되었다. Dynamic SGA는 관리자가 필요에 따라 SGA의 구성 요소 크기를 조정한 후 Oracle 인스턴스를 재시작하지 않고도 즉시 적용할 수 있는 기능이다 (단, Redo log buffer를 포함한 몇 가지는 제외된다). 이 기능을 사용하여 구성 요소의 크기를 변경할 때는 ALTER SYSTEM SET이라는 명령어를 사용한다. Database Buffer Cache 크기를 100MB로 변경하고 싶다면 아래와 같이 입력하면 된다:
SYS> ALTER SYSTEM SET DB_CACHE_SIZE=100M;
그러나 변경되는 크기가 정확하게 100MB가 되는 것은 아니다. Oracle에서는 메모리를 할당하는 새로운 단위인 Granule을 만들어 동적으로 크기를 조정한다. 이 Granule의 크기는 SGA_MAX_SIZE 파라미터의 크기에 따라 결정되며, Oracle 9i에서는 SGA_MAX_SIZE가 128MB 이하일 경우 1 Granule이 4MB로 설정되고, 128MB를 초과할 경우 1 Granule이 16MB로 설정된다. Oracle 10g 이후 버전에서는 SGA_MAX_SIZE의 기준이 조정되어 기존 128MB에서 1GB로 상향되었다. 즉, Oracle 10g 이후 버전에서는 SGA_MAX_SIZE가 1GB 이하일 경우 1 Granule이 4MB이고, 1GB를 초과하면 1 Granule이 16MB가 되는 것이다.
이와 같은 설정은 일종의 단위로, 명절에 친척들이 모여 할아버지께 세배를 드리면서 세뱃돈을 주는 상황을 비유할 수 있다. 중학생까지는 일괄적으로 1만 원을 주고, 고등학생부터는 5만 원을 주는 방식처럼, 한번에 주는 돈의 단위를 Granule이라고 할 수 있다.
현재 사용 중인 SGA 크기를 확인하려면 다음과 같이 조회할 수 있다:
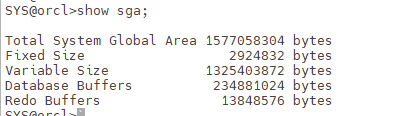
- Total System Global Area: 전체 SGA 양을 의미한다.
- Fixed Size: 백그라운드 프로세스들이 사용하는 공간으로 예약되어 있다.
- Variable Size: Shared Pool, Large Pool, Java Pool로 사용되는 공간이다.
- Database Buffers: DB Buffer Cache로 사용될 공간이다.
- Redo Buffers: Redo Log Buffer로 사용될 공간이다.
SGA MAX SIZE 확인하기
- NAME: sga_max_size
- TYPE: big integer
- VALUE: 160M
- NAME: shared_pool_size
- TYPE: big integer
- VALUE: 0
Database Buffer Cache의 크기 확인하기
- NAME: db_cache_size
- TYPE: big integer
- VALUE: 0

위 내용에서 shared_pool_size와 db_cache_size의 값이 0으로 나오는 이유는 Oracle 10g부터 적용된 ASMM (Automatic Shared Memory Management) 기능 때문이다. ASMM은 사용자가 SGA의 각 구성 요소 값을 지정하지 않아도 Oracle이 자동으로 SGA의 값을 결정하게 하여 성능을 향상시키는 기법이다. 각 구성 요소의 값을 잘못 설정할 경우 성능 저하 및 다양한 문제가 발생할 수 있으므로 Oracle이 스스로 최적의 값을 찾아서 사용하도록 하는 기술이다.
Granule 테스트
- SGA MAX SIZE가 160M로 1GB 미만이면 1 Granule이 4M로 계산되어 할당된다.

Program Global Area (PGA)의 주요 구성 요소
PGA는 Oracle 데이터베이스에서 각 프로세스가 사용하는 메모리 영역으로, 각 프로세스마다 별도로 존재하며 공유되지 않는다. 이는 SGA와 대조되는 개념으로, SGA는 여러 프로세스가 공유하는 반면, PGA는 개별 프로세스가 전용으로 사용하는 메모리이다.
PGA의 특징
- 개별적 메모리 공간: 각 프로세스는 자신의 PGA를 가지고 있으며, 이는 다른 프로세스와 공유되지 않고 데이터의 독립성과 안전성을 보장한다.
- 서버 프로세스 및 백그라운드 프로세스: 모든 서버 프로세스와 백그라운드 프로세스는 각각의 PGA를 가지며, 각자의 용도에 맞게 사용된다.
PGA의 주요 구성 요소
- Stack Memory: 각 프로세스의 실행에 필요한 데이터를 저장한다. 주로 프로시저 호출 시 필요한 지역 변수와 매개 변수를 저장한다.
- Heap Memory: 동적으로 할당된 메모리 블록을 저장하는 데 사용된다. 이는 다양한 크기의 데이터 구조를 생성하고 관리하는 데 유용한다.
- Session Memory: 세션 관련 정보를 저장한다. 사용자의 세션 정보, 상태, 세션 변수를 포함한다.
- Sort Area: 정렬 작업에 필요한 메모리 공간으로, 정렬된 결과를 저장하는 데 사용된다. 필요에 따라 할당된다.
- Cursor State: SQL 커서에 대한 상태 정보를 저장하여, 데이터베이스 쿼리 실행 시 필요한 정보를 제공한다.
Instance PGA
- Instance PGA는 데이터베이스 인스턴스 내에서 사용되는 PGA를 의미하며, 서버 프로세스가 사용하는 PGA의 일종이다. 이 PGA는 메모리의 효율적인 사용을 위해 동적으로 관리되며, 필요한 만큼 메모리를 할당하고 해제한다.

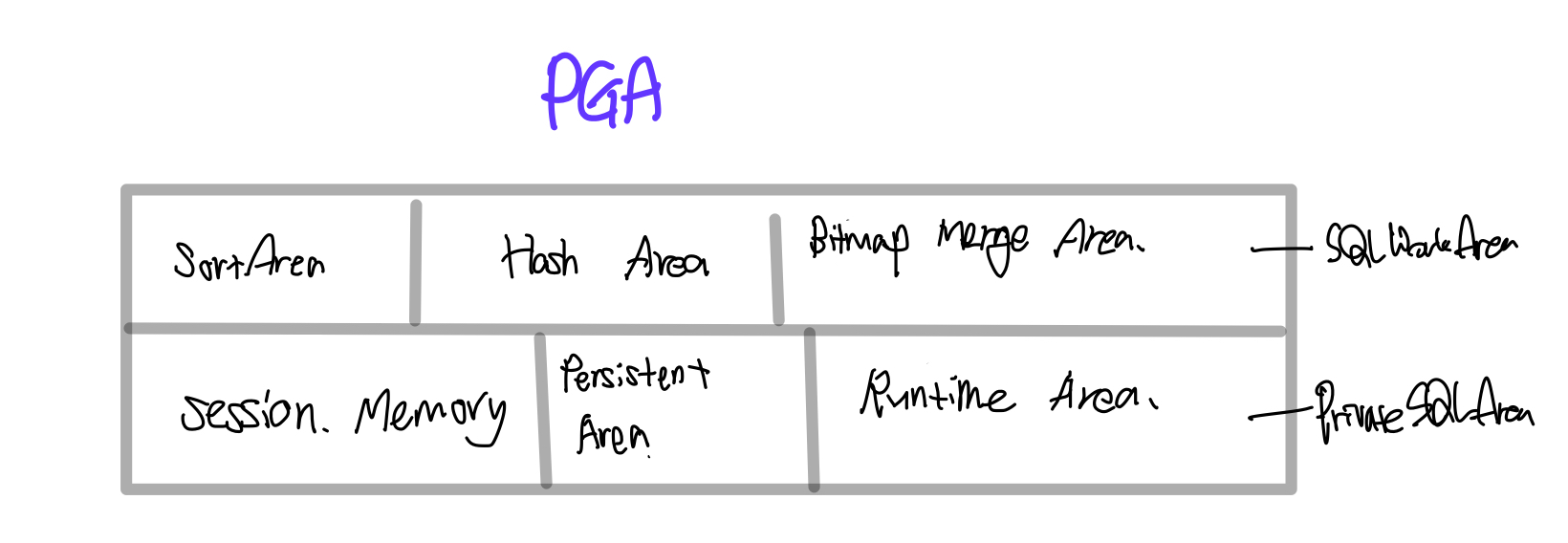
Private SQL Area
사용자가 SQL 문장을 수행하면, User Process는 Server Process에게 해당 쿼리를 전달한다. 이때, Server Process는 User Process의 정보를 Session Memory 부분에 저장한 후 SQL을 Parse 작업을 시작한다.
Bind 변수와 Private SQL Area
- 만약 SQL에 Bind 변수가 포함되어 있다면, Server Process는 해당 Bind 변수 값을 Private SQL Area에 보관한다. Bind 변수는 일반적으로 사용자가 입력하는 특정 값을 저장하는 변수이다.
Private SQL Area 구성
Private SQL Area는 두 가지 주요 영역으로 나누어진다:
- Persistent Area:
- 이 공간은 Bind 변수를 저장하는 데 사용된다. SQL 문장이 여러 번 실행될 때 Bind 변수의 값을 지속적으로 유지할 수 있도록 한다.
- Runtime Area:
- 이 공간은 SQL 문장을 실행하는 동안 임시로 데이터를 저장하는 데 사용된다. , 대량의 데이터를 조회하는 경우, 모든 데이터를 한 번에 DB Buffer Cache에서 PGA로 Fetch할 수 없으므로, Runtime Area에서 데이터를 임시로 저장하면서 점진적으로 Fetch하여 처리한다.
예시
가령, 100만 건의 데이터가 있는 테이블을 조회하는 경우, 데이터가 모두 DB Buffer Cache에서 PGA로 Fetch되어야 화면에 출력될 수 있다. 그러나 모든 데이터가 Fetch될 때까지 Runtime Area에서 데이터를 점진적으로 저장하게 된다. 이는 대량의 데이터를 효율적으로 처리하는 데 중요한 역할을 한다.
이와 같이 Private SQL Area는 SQL 실행 과정에서 매우 중요한 메모리 구조로, Bind 변수와 쿼리 실행 상태 정보를 관리하여 성능을 향상시키는 데 기여한다.
SQL Work Area
SQL Work Area는 주로 정렬, 해시 조인 및 집계와 같은 작업을 수행하기 위해 필요한 메모리 공간이다. SQL 문장의 실행 시 필요한 임시 데이터를 저장한다.
구성 요소
SQL Work Area는 다음과 같은 여러 구성 요소로 나누어진다:
- Sort Area: 정렬 작업에 필요한 공간이다.
- Hash Area: 해시 조인 및 해시 집계 작업에 필요한 공간이다.
- Merge Area: 정렬된 두 개의 데이터를 병합하는 데 필요한 공간이다.
- Create Area: 새로운 데이터를 생성할 때 필요한 공간이다.
초기 파라미터 설정
Oracle 8i 이전 버전에서는 이들 영역의 크기를 수동으로 설정해야 했다. 이때 사용되는 주요 파라미터는 다음과 같다:
- SORT_AREA_SIZE: 정렬 작업에 필요한 메모리의 크기.
- HASH_AREA_SIZE: 해시 작업에 필요한 메모리의 크기.
- MERGE_AREA_SIZE: 병합 작업에 필요한 메모리의 크.
- CREATE_AREA_SIZE: 데이터 생성을 위한 메모리의 크기.
이 파라미터는 초기화 파일에서 직접 설정하여 관리한다.
PGA Aggregate Target
Oracle 9i 이후부터는 PGA Aggregate Target을 설정하여 SQL Work Area의 크기를 동적으로 관리할 수 있다. 이 경우, WORKAREA_SIZE_POLICY 파라미터를 AUTO로 설정하면 Oracle Server가 메모리를 동적으로 관리하게 된다. 반면, MANUAL로 설정하면 이전과 같은 방식으로 각 파라미터 값을 수동으로 설정할 수 있다.
주의사항
- PGA_AGGREGATE_TARGET 값을 설정했다고 해서 각 Server Process가 그 값을 전부 사용할 수 있는 것은 아니다. , PGA_AGGREGATE_TARGET = 100M으로 설정한 경우, 각 Server Process는 PGA_MAX_SIZE 파라미터로 설정된 값만큼의 메모리만 사용할 수 있다.
PGA 용량 계산 방법
Oracle에서는 PGA 용량을 계산하기 위한 가이드라인을 제공하고 있다. OLTP(Online Transaction Processing) 시스템과 DSS(Decision Support System) 환경에 따라 PGA 용량 계산 공식을 달리한다.
PGA 용량 계산 공식
1. OLTP 시스템 환경일 경우:
\(
\text{PGA\_AGGREGATE\_TARGET} = (\text{총 물리 메모리 용량} \times 80\%) \times 20\%
\)
2. DSS 시스템 환경일 경우:
\(
\text{PGA\_AGGREGATE\_TARGET} = (\text{총 물리 메모리 용량} \times 80\%) \times 50\%
\)
총 물리 메모리가 16GB인 서버의 PGA 계산
- OLTP 시스템일 경우:
\(
\text{PGA\_AGGREGATE\_TARGET} = (16G \times 0.8) \times 0.2 = 2.56G
\)
- DSS 시스템일 경우:
\(
\text{PGA\_AGGREGATE\_TARGET} = (16G \times 0.8) \times 0.5 = 6.4G
\)
현재 Server의 PGA 관련 값 조회
현재 서버의 PGA와 관련된 값을 조회하려면 V$PGASTAT 뷰를 사용할 수 있다.
SELECT * FROM V$PGASTAT;
- aggregate PGA target parameter: 설정된 PGA의 총 목표 크기.
- aggregate PGA auto target: 자동으로 관리되는 PGA의 목표 크기.
- global memory bound: 전체 메모리 제한.
- total PGA inuse: 현재 사용 중인 PGA 메모리의 총량.
- total PGA allocated: 현재 할당된 PGA 메모리의 총량.
- maximum PGA allocated: 최대 할당된 PGA 메모리의 크기.
- total freeable PGA memory: 해제 가능한 PGA 메모리의 총량.
- process count: 현재 활성 프로세스의 수.
- max processes count: 최대 프로세스 수.
- PGA memory freed back to OS: OS에 반환된 PGA 메모리의 양.
- total PGA used for auto workareas: 자동 작업 영역에 사용된 총 PGA 메모리.
- maximum PGA used for auto workareas: 자동 작업 영역에 대한 최대 PGA 메모리 사용량.
- total PGA used for manual workareas: 수동 작업 영역에 사용된 총 PGA 메모리.
- maximum PGA used for manual workareas: 수동 작업 영역에 대한 최대 PGA 메모리 사용량.
- over allocation count: 과다 할당된 횟수.
- bytes processed: 처리된 바이트 수.
- extra bytes read/written: 추가로 읽거나 쓴 바이트 수.
- cache hit percentage: 캐시 적중 비율.
- recompute count (total): 총 재계산 횟수.
.
■ SQL 문장 실행 원리

사용자가 SQL 문장을 실행하면, 사용자의 PC에 있는 User Process가 해당 SQL 문장을 서버로 전달한다.
User Process는 SQL 문장을 작성하고 실행할 수 있는 프로그램으로, 일반적으로 SQL*Plus, SQL Developer, Toad와 같은 도구가 사용된다. 사용자가 이러한 프로그램을 통해 SQL 문장을 실행하면, 프로그램은 서버에서 실제 작업을 수행하는 Server Process를 찾아 SQL 문장을 전달한다. 이후 User Process는 Server Process가 결과를 반환할 때까지 대기한다.
- User Process에서 SQL 전달:
사용자가 SQL 문장을 실행하면 User Process가 이를 Server Process로 전달하고, 결과를 받을 때까지 기다린다. - Server Process의 SQL 구문 처리:
Server Process는 User Process로부터 받은 SQL 문장을 문법 검사(Syntax Check)와 의미 검사(Semantic Check), 권한 검사 순으로 점검한다. 이때 권한 검사는 사용자가 SQL에서 사용하는 객체에 접근 권한이 있는지 확인하는 과정이다. 이 전체 과정은 Parse라고 하며, 프로그래밍에서 소스 코드를 컴파일하는 단계와 유사하다고 볼 수 있다. - Library Cache 검토:
Parse 과정이 완료되면, Shared Pool의 Library Cache에 해당 SQL 문장이 이미 실행된 적이 있는지 확인한다. Library Cache는 실행된 SQL 문장과 그 실행 계획이 저장되는 공간이다. - Soft Parse와 Hard Parse:
- Soft Parse: 실행 계획이 Library Cache에 존재하면 해당 계획을 재사용하고 즉시 실행(Execution) 단계로 넘어간다.
- Hard Parse: 실행 계획이 없을 경우, 옵티마이저가 새로운 실행 계획을 생성하게 되는데, 이 과정은 더 많은 자원을 소모한다.
옵티마이저는 SQL 문의 실행 계획을 최적화하는 데 내비게이션처럼 최적 경로를 찾아주는 역할을 한다고 볼 수 있다. 서버 프로세스가 옵티마이저에게 요청을 보내면 옵티마이저는 데이터 딕셔너리(Data Dictionary) 등을 참조해 실행 계획을 생성한다. 이 과정은 Soft Parse보다 더 많은 시간과 자원을 소모하기 때문에 Hard Parse라고 부른다.
- Soft Parse와 Hard Parse의 차이:
- Soft Parse는 이전에 사용된 실행 계획을 재사용하므로 빠르고 자원 소모가 적다.
- Hard Parse는 옵티마이저가 새롭게 실행 계획을 생성해야 하므로 시간이 많이 걸린다.
생성된 실행 계획은 Library Cache에 저장되고, 이후 PGA에 복사되어 실행된다. 이 과정을 통해 SQL 문이 효율적으로 실행된다.
Select 문장의 실행 원리:
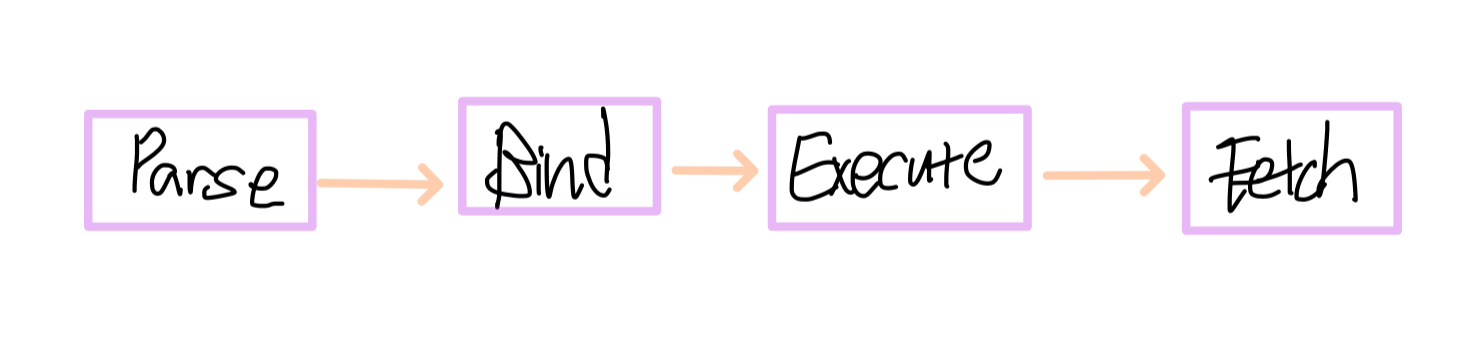
사용자가 Select 문을 실행할 때 서버에서는 네 가지 주요 단계를 거쳐 해당 문장이 수행된다.
Parse (구문 분석 단계)
사용자가 SQL 문장을 실행하면, User Process가 Server Process로 해당 SQL 문장을 전달한다.
- Parse Tree 생성: 서버 프로세스는 SQL 문을 분석하여, 키워드와 컬럼명 등을 구분하고 Parse Tree라는 구조를 생성한다. 이 과정에서 문법 검사(Syntax Check)가 이루어진다. 구문이 정확하다면, 그다음에 의미 검사(Semantic Check)를 수행하여 논리적 오류가 있는지 확인한다. :
- 키워드 오타가 있을 경우 구문 단계에서 오류 발생
- 존재하지 않는 테이블을 조회할 경우 의미 검사 단계에서 오류 발생
- Dictionary Cache 활용: 이 과정에서 필요한 테이블과 컬럼 정보는 Dictionary Cache (또는 Row Cache)에 저장된 데이터를 통해 확인하며, 데이터 딕셔너리 조회로 인한 성능 저하를 최소화한다.
- SQL 문장 해시화: 구문 분석과 의미 검사 후, SQL 문장을 ASCII 값(숫자값)으로 변환하고, 이를 다시 해시 함수를 통해 특정 해시 값으로 변환한다. 이 해시 값은 Shared Pool의 Library Cache에 있는 기존 해시 값들과 비교하여 동일한 문장이 있는지 확인한다. 이 과정을 커서 공유(Cursor Sharing) 또는 Soft Parse라고 한다.
- Soft Parse와 주의 사항: 동일한 SQL 문장이라도 사용자(scott, hr 등)가 다르면 다른 문장으로 간주되어 별도의 커서가 생성될 수 있다.
Hash 함수의 역할과 활용
오라클 데이터베이스에서는 사용자가 입력한 SQL 문장을 해시 함수(Hash Function)를 통해 고유한 해시 값으로 변환하여, Library Cache에 동일한 SQL 문이 존재하는지 빠르게 확인한다. 이 과정을 통해 SQL 문장이 이미 캐시에 있는 경우 실행 계획을 재사용하는 Soft Parse가 가능해져 성능이 향상된다.
- Hash 함수의 원리
해시 함수는 동일한 입력값이 주어질 때는 항상 같은 결과값(해시 값)을 반환하며, 다른 입력값이 주어지면 결과값이 달라지도록 보장한다. 이 성질은 데이터 비교와 같은 상황에서 매우 유용하게 사용된다. - 오라클에서의 활용
- SQL 중복 검사: SQL 문장이 해시 함수에 의해 변환된 해시 값을 통해, Library Cache에 동일한 SQL 문장이 있는지 확인한다.
- 데이터 비교: 두 데이터가 동일한지 확인할 때 해시 값을 비교하여 일치 여부를 판단한다.
- Hash Join: 대용량의 데이터 집합을 조인할 때 인덱스를 사용하지 않고도 빠르게 비교할 수 있다. 해시 함수가 두 테이블의 조인 컬럼을 해시 값으로 변환하고, 해시 값을 비교하여 빠르고 정확하게 조인을 수행한다.
이러한 특성 덕분에 해시 함수는 성능이 빠르고 정확하며, 대용량 데이터 처리와 조인 시 유용하게 사용된다.
Hash Bucket
-
- 해시 함수가 생성한 해시 값을 기반으로 해시 버킷(Hash Bucket)에 SQL 문장이 저장된다.
- 사용자가 SQL 문을 실행할 때, 이 문장이 Library Cache에 이미 존재하는지 확인하기 위해 먼저 해시 버킷을 탐색한다.
- 해시 버킷은 동일한 해시 값을 가진 SQL 문장들이 모이는 공간으로, 이 공간을 탐색하여 SQL 문장이 캐시에 존재하는지 빠르게 찾을 수 있다.
Cursor (커서)
- 해시 버킷 아래에는 동일한 해시 값을 가진 여러 SQL 문장들이 커서(Cursor) 형태로 저장된다.
- 커서는 SQL 문장의 실제 실행 계획, 상태 정보 등을 포함하는 데이터 구조로, SQL 문장이 어떻게 실행될지에 대한 정보를 담고 있다.
- 동일한 해시 값이더라도 SQL 문장의 구체적인 내용(예: 대소문자 차이, 공백 등)이 다를 수 있기 때문에, 정확한 SQL 문장을 찾기 위해 커서를 탐색하게 된다.
SQL 문장의 해시 값을 기반으로 먼저 해시 버킷을 찾고, 그 아래에서 커서를 탐색하여 최종적으로 SQL 문장을 식별한다. 이러한 구조 덕분에 오라클은 캐싱된 SQL 문장을 효율적으로 재사용하고, 불필요한 재파싱을 줄여 성능을 향상시킨다.
Oracle의 커서(Cursor)는 메모리에 데이터를 저장해 SQL 문장을 실행하고 재사용하기 위해 만들어진 일시적인 작업 공간이다. 주로 다음과 같은 세 종류가 있다:
공유 커서 (Shared Cursor):
- Library Cache에 있는 커서를 의미한다. 공유 커서는 SQL 문장이 이전에 실행되었을 때의 실행 계획과 관련 정보를 보관하여, 동일한 SQL 문장을 재사용할 때 불필요한 재파싱을 줄이고 성능을 높인다.
- 이 과정을 통해 Soft Parse가 가능해지며, 이는 Hard Parse에 비해 빠르게 실행 계획을 참조할 수 있는 방식이다.
- 마치 사람이 이미 익숙한 길을 기억에 따라 찾아가는 것처럼, Oracle은 동일한 SQL 문장의 실행 계획을 기억하고 재사용하여 성능을 향상시킨다.
세션 커서 (Session Cursor)와 어플리케이션 커서 (Application Cursor):
- 주로 특정 사용자 세션이나 어플리케이션에서만 사용하는 커서를 의미한다.
커서 공유의 제한점
모든 SQL 문장이 공유 커서로 재사용될 수 있는 것은 아니다. 아래와 같은 조건에 따라 커서 공유가 제한될 수 있다:
- 사용자가 다를 경우: 다른 사용자가 SQL 문장을 실행하면 새로운 커서가 생성될 수 있다.
- 옵티마이저 모드가 다를 경우: SQL 최적화 설정이 다를 경우, 다른 실행 계획이 필요할 수 있어 동일한 커서를 사용할 수 없다.
부모 커서와 자식 커서
- 부모 커서 (Parent Cursor): SQL 문장의 본문을 보관하며, 실행 계획과 관련된 주요 정보를 담고 있다.
- 자식 커서 (Child Cursor): 사용자 세션 정보, 옵티마이저 모드 등 실행 환경에 따라 구체적으로 변동되는 정보를 담고 있어, 같은 SQL 문장이라도 환경에 따라 자식 커서를 생성하여 관리한다.
Oracle에서는 동일한 SQL 문장을 실행하더라도 각 사용자가 다른 계정으로 데이터베이스에 로그인한 경우, 동일한 Parent Cursor를 공유하더라도 각기 다른 Child Cursor가 생성된다. 즉, 각 사용자가 DB에 로그인할 때마다 새로운 환경(세션)이 생성되고, 이 환경에 따라 커서가 분리되므로 공유가 어려워진다.
예: 10명의 사용자, 1개의 Parent Cursor, 10개의 Child Cursor
만약 10명의 사용자가 동일한 SQL 문장을 실행하지만 각기 다른 계정으로 로그인한 경우:
- Parent Cursor는 하나만 생성되지만,
- Child Cursor는 사용자별로 하나씩 총 10개가 생성된다.
이로 인해 커서 공유가 제한되고, Library Cache에 불필요한 Child Cursor가 증가하게 되어 캐시 효율성이 떨어질 수 있다.
Hash List의 역할
Oracle은 성능 저하를 방지하기 위해, 커서의 실행 계획이나 위치 등을 일일이 탐색하지 않고 Hash List라는 자료구조로 관리한다.
- Hash List는 각 커서가 어떤 데이터나 실행 계획을 포함하는지 체인 구조로 연결해 빠르게 검색할 수 있도록 한다.
- 이는 마치 자전거 체인처럼, Chain 구조를 통해 다음 커서를 빠르게 참조하여 SQL 실행 계획을 찾는 시간을 줄여준다.
Oracle의 Library Cache 구조에서는 다수의 사용자가 동시에 SQL 문장을 실행할 때, Hash List가 하나만 존재하여 자원을 효율적으로 관리하지만, 다수의 사용자가 동시 접근할 경우 경쟁 문제가 발생할 수 있다.
Hash List와 경쟁 상황
- 사용자가 SQL 문장을 실행하면 해당 문장이 Hash 함수를 통해 특정 Hash Value로 변환된다.
- 이 Hash Value는 Hash Bucket을 통해 해당 SQL 문장이나 실행 계획이 존재하는 위치를 찾게 만든다.
- Oracle은 이 과정에서 Heap 구조를 사용하여 메모리를 효율적으로 관리하는데, 이 구조는 데이터를 저장할 때는 빠르지만, 데이터가 순서 없이 배치되어 검색 시 시간이 걸리는 단점이 있다.
경쟁 문제
문제는 Library Cache의 Hash List가 단일 구조라는 점이다. 만약 10명의 사용자가 동시에 SQL 문장을 실행하여 Parse 단계에 진입한다면, 이들은 모두 Library Cache의 동일한 Hash List에 접근해야 한다.
- 경쟁 발생: 10명이 동시에 Hash List를 읽고자 할 때, 단일 출석부를 여러 학생이 동시에 찾으려는 것처럼 순서를 기다려야 하는 상황이 생긴다.
- 병목현상: 단일 리스트를 사용함으로써 발생하는 이 경쟁이 병목현상을 일으켜 성능 저하로 이어질 수 있다.
이러한 경쟁 상황을 줄이기 위해 Oracle은 Latch 메커니즘과 같은 잠금 기법을 적용하여 데이터 일관성을 보장하고 성능 저하를 최소화하려 노력한다.
Oracle에서는 Library Cache에 대한 접근을 조절하기 위해 Library Cache Latch를 도입하여 경쟁 문제를 관리하고 성능 저하를 방지한다. Latch는 일종의 잠금 장치로, 여러 사용자가 동시에 Library Cache를 탐색하려고 할 때 한 명의 사용자만이 성공적으로 접근할 수 있도록 하고 나머지 사용자들은 대기하게 된다.
Library Cache Latch의 역할
- 경쟁 조절: 동시에 Library Cache에 접근하려는 여러 사용자 중 1명만 접근을 허용하고 나머지는 대기하도록 하여 경쟁 상태를 관리한다.
- 성능 저하 방지: 이 잠금 메커니즘을 통해 시스템의 성능 저하를 최소화한다.
Select와 Update의 차이
- Select의 경우: 사용자가 SQL 문장을 실행했을 때 Hash List를 조회하여 원하는 SQL 문장과 실행 계획이 있는지를 확인한다. 만약 해당 문장이 이미 존재한다면 Soft Parse를 통해 재사용할 수 있다.
- Update의 경우: 만약 사용자가 처음으로 SQL 문장을 실행하려는 경우(즉, Hash List에 존재하지 않는 경우)에는 Hard Parse 과정을 통해 새로운 실행 계획을 생성하고 이를 Library Cache에 등록하게 된다.
Soft Parse와 Hard Parse
- Soft Parse: 이미 존재하는 SQL 문장을 재사용하는 과정으로, 성능이 상대적으로 빠르다. 하지만, 사용자 수가 많거나 경쟁이 심한 경우 여전히 느릴 수 있다.
- Hard Parse: 새로운 SQL 문장을 실행하기 위한 과정으로, 성능이 저하될 수 있다.
Session Cached Cursor
Oracle은 이러한 Soft Parse의 성능 저하를 해결하기 위해 Session Cached Cursor라는 파라미터를 제공한다. 이 기능은 자주 사용되는 SQL 문장을 각 세션에 캐시하여, 해당 세션에서 재사용할 수 있도록 하여 성능을 향상시키는 방법이다.
결론적으로, Soft Parse와 Hard Parse의 성능 차이는 명확하며, Oracle에서는 성능 최적화를 위해 다양한 메커니즘을 통해 이 문제를 관리하고 있다.
Oracle의 옵티마이저는 SQL 문장을 실행하기 위한 최적의 실행 계획을 수립하는 데 핵심적인 역할을 하며, 다양한 방법과 기법을 통해 가장 효율적인 경로를 결정한다. 옵티마이저가 실행 계획을 생성하는 과정과 그 방법은 다음과 같다.
옵티마이저의 작동 방식
- 통계 정보 활용:
- 옵티마이저는 테이블, 인덱스, 조인 등에 대한 통계 정보를 수집한다. 이 통계는 데이터 분포, 테이블 크기, 인덱스의 선택도 등으로, 실행 계획을 결정하는 데 중요한 기준이 된다.
- 통계 정보는 주기적으로 갱신되며, 사용자는 수동으로도 갱신할 수 있다.
- 비용 기반 옵티마이저 (Cost-Based Optimizer, CBO):
- 대부분의 경우 Oracle은 비용 기반 옵티마이저를 사용한다. CBO는 다양한 실행 계획을 생성한 후 각 계획의 비용을 계산하여 가장 낮은 비용을 가진 실행 계획을 선택한다.
- 비용은 CPU 시간, I/O 작업 수, 메모리 사용량 등 여러 요소를 고려하여 계산된다.
- 규칙 기반 옵티마이저 (Rule-Based Optimizer, RBO):
- 예전의 Oracle 버전에서는 규칙 기반 옵티마이저도 사용되었다. 이 방법은 사전 정의된 규칙에 따라 실행 계획을 결정하는 방식으로, 현재는 CBO에 비해 사용되지 않는다.
- 하지만 RBO는 여전히 일부 환경에서 활용되기도 한다.
- 실행 계획 생성:
- 옵티마이저는 SQL 문을 해석하고, 어떤 테이블을 먼저 읽어야 하는지, 어떤 조인 방법을 사용할지, 인덱스를 활용할지 여부 등을 결정한다.
- 이를 통해 최적의 경로를 찾아내고, 생성된 실행 계획을 사용자에게 반환한다.
- 힌트 사용:
- 필요에 따라 사용자는 SQL 문에 힌트를 추가하여 옵티마이저의 선택을 유도할 수 있다. 힌트는 특정 인덱스 사용이나 조인 방법 등을 지정할 수 있게 해준다.
- 이를 통해 성능을 더욱 개선할 수 있다.
- 실행 계획 캐싱:
- 이미 실행된 SQL 문장은 Library Cache에 저장되어 재사용될 수 있다. 이렇게 함으로써 성능을 높이고, Hard Parse의 빈도를 줄여주는 효과가 있다.
Rule-Based Optimizer (RBO)
- 정적인 규칙 사용:
- RBO는 미리 정의된 규칙 세트를 기반으로 실행 계획을 수립한다. 각 규칙은 특정한 상황에서 사용될 수 있는 접근 방식을 제공한다.
- 규칙의 우선순위:
- RBO는 실행 계획을 수립하기 위해 아래와 같은 우선순위로 규칙을 적용한다.
- 1위: ROWID에 의한 단일 행 접근 (1st: Single row access by ROWID)
- 2위: 클러스터 조인 (2nd: Cluster join)
- 3위: 해시 클러스터 키에 의한 단일 행 접근 (3rd: Single row access by hash cluster key)
- 4위: 유니크 또는 기본 키에 의한 단일 행 접근 (4th: Single row access by unique or primary key)
- 5위: 클러스터 조인 (5th: Cluster join)
- 6위: 해시 클러스터 키 (6th: Hash cluster key)
- 7위: 인덱스 클러스터 키 (7th: Indexed cluster key)
- 8위: 복합 인덱스 (8th: Composite index)
- 9위: 단일 열 인덱스 (9th: Single-column index)
- 10위: 인덱스 열에 대한 한정 범위 검색 (10th: Bounded range search on indexed columns)
- 11위: 인덱스 열에 대한 무제한 범위 검색 (11th: Unbounded range search on indexed columns)
- 12위: 정렬-병합 조인 (12th: Sort-merge join)
- 13위: 인덱스 열의 MAX 또는 MIN (13th: MAX or MIN of indexed column)
- 14위: 인덱스 열의 ORDER BY (14th: ORDER BY on indexed column)
- 15위: 전체 테이블 스캔 (15th: Full table scan)
- RBO는 실행 계획을 수립하기 위해 아래와 같은 우선순위로 규칙을 적용한다.
-
- 사용자가 SELECT * FROM emp WHERE empno=7902;라는 SQL을 실행했을 때, empno 열에 인덱스가 존재한다면 RBO는 위의 규칙을 하나씩 적용하여 실행 계획을 찾는다. 규칙 15번(전체 테이블 스캔)부터 시작하여, 해당 쿼리에 맞는 방법이 발견될 때까지 규칙을 차례로 시도한다. 이 과정에서 모든 SQL이 15가지 규칙 내에서 실행 계획을 만들어야 하는 점이 문제이다.
- 제한점:
- RBO는 정적인 규칙을 사용하기 때문에, 데이터베이스의 상황이나 데이터 분포가 변할 때 최적의 실행 계획을 생성하지 못할 수 있어 성능 저하로 이어질 수 있다.
Cost-Based Optimizer (CBO)
- 동적인 비용 계산:
- CBO는 데이터베이스의 현재 상태와 통계 정보를 바탕으로 여러 실행 계획의 비용을 계산한다. 이 비용은 CPU 시간, 디스크 I/O, 메모리 사용 등을 포함한다.
- 최적의 계획 선택:
- CBO는 여러 실행 계획을 생성하고, 각 계획의 비용을 비교하여 가장 낮은 비용을 가진 실행 계획을 선택한다. 데이터의 분포와 양에 따라 최적의 방법이 달라질 수 있다.
- 유연성:
- CBO는 다양한 데이터 분포와 상황에 따라 적절한 실행 계획을 생성할 수 있어, 더 나은 성능을 제공한다.
- 기타 요소 고려:
- CBO는 인덱스의 사용 여부, 조인 순서, 필터링 조건 등을 종합적으로 분석하여 실행 계획을 수립한다.
RBO는 미리 정의된 규칙에 따라 실행 계획을 생성하는 반면, CBO는 현재 데이터베이스의 상태와 통계 정보를 기반으로 동적으로 실행 계획을 생성한다. RBO는 정적인 접근 방식으로 인해 데이터 분포 변화에 유연하지 않지만, CBO는 최적의 실행 계획을 보다 효과적으로 선택할 수 있다. 현재 Oracle에서는 CBO가 기본적으로 사용되고 있으며, RBO는 주로 레거시 시스템에서 활용된다.
Rule-Based Optimizer (RBO) vs. Cost-Based Optimizer (CBO)
- 제한된 실행 계획:
- RBO는 15가지의 규칙 내에서 실행 계획을 세워야 하므로, 다양한 상황에서 최적의 계획을 제공하지 못할 수 있다.
- 인덱스 사용:
- 인덱스는 항상 사용하는 것이 아니라, 상황에 따라 다를 수 있다. 교통 체증 시 택시를 타는 것보다 걷는 것이 더 빠를 수 있다.
- RBO의 발전:
- RBO는 Oracle 7 이후로 규칙이 추가되지 않았으며, 10g R2부터는 완전히 지원되지 않는다. 즉, Oracle 11g부터는 CBO만 지원된다.
- CBO의 등장:
- CBO는 RBO와 다르게 현실적인 상황을 기반으로 실행 계획을 세우며, 데이터딕셔너리 정보(DBA_TABLES, USER_TABLES 등)를 참조하여 실행 계획을 결정한다.
- 옵티마이저의 중요성:
- 옵티마이저의 실행 계획이 SQL 문장의 수행 속도에 절대적인 영향을 미친다. 좋은 실행 계획이 없으면 쿼리 성능이 저하되고, 반대로 좋은 실행 계획은 쿼리 성능을 크게 향상시킨다.
- Hard Parse vs. Soft Parse:
- 새로운 실행 계획을 세우는 과정을 Hard Parse라고 하며, 이는 Soft Parse에 비해 훨씬 더 많은 시간이 소요된다. 따라서 가능한 Soft Parse를 수행할 수 있도록 쿼리를 작성해야 한다.
SQL 수행 속도와 옵티마이저
- 업데이트와 최신 정보:
- 옵티마이저가 사용하는 데이터 사전 정보는 특정한 경우에 자동으로 업데이트되지만, 항상 최신 정보를 반영하는 것은 아니다. 따라서 SQL의 수행 속도는 옵티마이저의 실행 계획에 따라 달라지지만, 이 실행 계획이 참조하는 Data Dictionary 관리는 사람이 관리해야 한다.
- 좋은 실행 계획을 위한 관리:
- 좋은 실행 계획을 만들기 위해서는 적절한 인덱스를 생성하고, 데이터 공간을 효과적으로 관리하는 등 관리자의 역할이 중요하다. 이는 마치 네비게이션이 만들어진 길 중에서 가장 빠른 길을 찾아주는 것과 유사한다.
- 인프라 관리의 중요성:
- 네비게이션은 빠른 길을 제시하지만, 실제로 빠른 길을 만들고 최신의 내비게이션 지도를 유지하는 것은 관리자의 몫이다. SQL 성능을 최적화하기 위해서는 데이터베이스 관리자가 지속적으로 데이터베이스 상태를 점검하고 필요한 조치를 취해야 한다.
- 자동 관리 기능:
- Oracle의 최신 버전에서는 데이터 사전 정보를 자동으로 수집하고 관리하는 기능이 제공되므로, 이러한 기능을 활용하여 데이터베이스 성능을 높일 수 있다. 그러나 여전히 관리자의 주의가 필요한 부분이 존재한다.
Oracle Shared Pool과 관리
- Shared Pool의 개념:
- Shared Pool은 Oracle 데이터베이스에서 SQL 문장과 실행 계획을 공유하는 메모리 영역으로, 커서 공유 및 효율적인 메모리 사용을 위해 필요하다.
- Parameter Shared Pool Size:
- shared_pool_size 파라미터는 Shared Pool의 크기를 설정하는 데 사용된다. 이 값은 데이터베이스의 성능에 직접적인 영향을 미친다.
- Automatic Shared Memory Management (ASMM):
- ASMM 기능이 도입되어, sga_target과 pga_aggregate_target 같은 파라미터로 Shared Memory를 자동으로 관리할 수 있게 되었다. 이를 통해 데이터베이스 관리자가 수동으로 메모리 크기를 조정할 필요가 줄어들었다.
- 최소 크기 설정:
- shared_pool_size를 설정할 때 최소값을 지정할 수 있으며, 이 값은 바이트 단위로 시작한다. 만약 설정한 값이 현재 사용 중인 크기를 초과하는 경우, 데이터베이스는 기존 메모리 사용량을 고려하여 조정한다.
- 현재 Shared Pool 사용량 확인:
- Shared Pool의 현재 사용량과 설정된 크기를 확인하기 위해 아래 쿼리를 실행할 수 있다:
- Shared Pool의 현재 사용량과 설정된 크기를 확인하기 위해 아래 쿼리를 실행할 수 있다:
SELECT * FROM v$sgastat WHERE pool = 'shared pool';
BIND(바인드) 과정
- BIND의
- BIND 과정은 SQL 문장을 실행하기 위한 두 번째 단계로, 실행할 SQL에서 변수를 설정하는 과정을 의미한다. 이를 통해 동일한 SQL 문을 여러 번 실행할 때 발생하는 부담을 줄일 수 있다.
-
- 학생 1,000명이 있는 학교에서 학생의 학번과 이름을 입력받아 전체 평균 점수와 영어 과목 점수를 조회한다고 가정한다.
- 만약 1,000명의 학생 정보를 각각 조회한다면, 학번과 이름만 다르고 SQL 실행 계획은 동일하므로, SQL 문을 1,000번 파싱하고 실행 계획을 1,000개 생성하는 것보다 한 번만 파싱하고 실행 계획을 한 개만 생성한 후, 학번과 이름만 바꾸어 1,000번 실행하는 것이 효율적이다.
- 바인드 변수:
- 학번과 이름을 바인드 변수로 사용하게 되면, 동일한 실행 계획을 여러 번 재사용할 수 있어 SQL 성능이 향상된다.
- 바인드 변수를 통해 Soft Parse를 많이 수행할 수 있어 쿼리 수행 속도가 빨라진다.
- Skewed 데이터 문제:
- 그러나 테이블의 데이터가 고르게 분포되지 않고 특정 데이터에 편중되어 있을 경우(Skewed), 바인드 변수가 정상적으로 작동하지 않을 수 있다.
- Skewed란 테이블에 있는 데이터들이 균일한 비율이 아니라 특정 데이터가 집중적으로 많은 상황을 의미한다.
- Histogram 생성:
- 이럴 경우, 특수한 통계 정보인 Histogram을 생성하여 문제를 해결해야 한다. 하지만 Histogram을 생성하면 바인드 기능을 사용할 수 없게 된다.
- 따라서 SQL을 작성할 때는 바인드 기능을 활용할 수 있도록 주의해야 한다.
Execute(실행) 과정
- Execute의
- Execute 과정은 SQL 문이 준비된 후 실제로 데이터베이스에서 작업을 수행하는 단계이다. 이 과정에서는 필요한 데이터를 검색하고, 조작하며 결과를 반환하는 작업이 이루어진다.
- Bind와 Execute의 관계:
- Bind 과정에서 설정된 변수를 기반으로 SQL 문이 실행되며, 사용자 요구에 따라 필요한 데이터를 찾는다.
- SQL 문이 실행되면, 해당 데이터가 데이터베이스 버퍼 캐시(Database Buffer Cache)로 복사되어 필요한 작업이 이루어진다.
- Database Buffer Cache:
- Database Buffer Cache는 메모리 내의 특정 영역으로, 디스크의 데이터를 메모리로 가져와서 효율적으로 작업할 수 있도록 한다.
- 서버 프로세스는 먼저 Database Buffer Cache에서 원하는 블록이 존재하는지 확인한다.
- 해시 함수와 블록 검색:
- Database Buffer Cache에서 프로세스가 찾는 블록이 있는지 확인하는 원리는, 서버 프로세스가 찾고자 하는 블록의 주소를 해시 함수에 넣어 해시 값을 생성한다.
- 생성된 해시 값은 Database Buffer Cache의 해시 리스트와 비교되어 동일한 해시 값이 존재하는지를 검사한다.
- 블록의 존재 여부에 따른 처리:
- 만약 Database Buffer Cache에 원하는 블록이 존재하면, 다음 단계인 Fetch 단계로 진행된다.
- 반대로, 원하는 블록을 찾지 못한 경우, 서버 프로세스는 하드 디스크에서 해당 블록을 찾아 Database Buffer Cache로 복사한다.
- 메모리 작업의 일반 원리:
- 하드 디스크에서 필요한 블록이나 파일을 찾아 메모리로 복사한 후 작업을 수행하는 원리는 Oracle뿐만 아니라 대부분의 프로그램에서 동일하게 적용된다.
- , 워드 프로그램에서도 파일을 열기 위해 하드 디스크에서 데이터를 읽어 메모리로 가져온 후 편집 작업을 수행한다.
Execute 과정은 SQL 문을 실제로 실행하여 결과를 반환하는 중요한 단계로, Database Buffer Cache와 해시 값 비교를 통해 필요한 데이터를 효율적으로 검색하는 방법을 사용한다.
실행(Execute) 과정
- 파일을 메모리로 불러오는 과정의
- 사용자가 report.doc라는 100페이지짜리 파일에서 5번째 페이지의 내용을 수정하고 싶다고 가정하면, 하드디스크에 저장된 해당 파일을 열어서 메모리(RAM)로 불러온다.
- 일반 프로그램에서는 수정이 필요한 페이지만 불러오는 것이 아니라 파일 전체를 메모리로 복사한 후, 메모리에서 작업을 진행하게 된다.
- 오라클의 메모리 작업 방식:
- 오라클도 모든 작업을 메모리에서 수행한다는 점은 일반 프로그램과 같다.
- 그러나 오라클은 특정 파일 내에서 필요한 데이터가 들어있는 블록만을 메모리로 가져올 수 있다는 점이 다른다.
- 데이터베이스 파일의 크기가 매우 크기 때문에, 오라클이 파일 전체를 메모리에 복사하지 않고 필요한 블록만 복사해오는 것은 매우 효율적이다.
- 실행 단계
- 실행(Execute) 단계란, 하드디스크의 데이터 파일에서 필요한 데이터를 포함한 블록을 찾아 메모리(Database Buffer Cache)로 복사해오는 과정이다.
- 사용자가 조회, 수정, 또는 새로운 입력 작업을 하기 위해서는 해당 테이블의 데이터가 Database Buffer Cache에 존재해야 한다.
- Database Buffer Cache에서의 데이터 관리:
- 만약 필요한 데이터가 Database Buffer Cache에 없다면, 서버 프로세스는 하드디스크에 있는 데이터 파일로 가서 해당 블록을 찾는다.
- 찾은 블록을 Database Buffer Cache로 복사해 온 후, 그 블록을 메모리에서 사용하여 필요한 작업을 수행하게 된다.
오라클에서는 데이터를 조회하거나 수정할 때, 필요한 데이터가 들어있는 블록만을 메모리로 가져와 효율적으로 작업을 수행한다. 이는 큰 데이터 파일 전체를 메모리로 불러오는 대신, 필요한 부분만 메모리(Database Buffer Cache)로 불러오는 방식으로, 성능과 자원 활용 면에서 큰 장점이 있다.
Block 단위의 I/O
- DB BLOCK SIZE:
- 오라클은 하드디스크에 저장된 데이터 파일에서 데이터를 읽어 메모리(Database Buffer Cache)로 옮기거나 데이터를 파일에 저장할 때 Block 단위로 작업을 수행한다.
- Block 크기는 데이터베이스 생성 시 DB BLOCK_SIZE 파라미터로 설정되며, 이후에는 DB를 재생성하지 않는 이상 변경할 수 없다.
- 오라클 9i의 기본 블록 크기는 4KB이며, 10g 이후부터는 기본 블록 크기가 8KB로 증가했다.
- Block 크기 설정의 중요성:
- 블록 크기가 크면 한 번에 더 많은 데이터를 읽거나 쓸 수 있어 I/O 작업을 줄이는 장점이 있다.
- 그러나 블록 크기가 너무 크면 불필요하게 많은 공간을 차지할 수 있으며, Database Buffer Cache에서 대기(wait) 상황이 발생하여 성능이 저하될 수 있다.
- 따라서 블록 크기는 성능과 자원 효율성을 위해 신중하게 고려해야 한다.
- Block 단위로 이동하는 데이터:
- Block은 여러 개의 데이터를 포함한 작은 단위의 데이터 묶음으로, 데이터를 담아 메모리와 하드디스크 사이를 이동한다.
- 또한, Database Buffer Cache에서 데이터를 데이터 파일에 저장할 때도 Block 단위로 처리된다.
오라클에서 데이터 이동은 Block 단위로 수행되며, 블록 크기는 데이터베이스 성능에 중요한 영향을 미치며 블록 크기 설정은 I/O 작업 최적화와 캐시 효율성을 고려하여 신중하게 결정해야 한다.
매장과 창고를 통한 이해
- 매장에 물건이 있는 경우:
- 손님이 매장에 있는 직원에게 원하는 물건을 요청한다.
- 만약 매장에 물건이 있다면, 손님은 즉시 그 물건을 구매할 수 있다.
- 매장에 물건이 없는 경우:
- 매장에 물건이 없고 창고에만 있다면, 직원은 손님을 기다리게 하고 창고로 가서 물건을 찾아야 한다.
- 창고에 많은 물건이 쌓여 있고, 손님이 찾는 물건이 쉽게 보이지 않으면 시간이 오래 걸릴 수 있다.
- 이로 인해 손님이 오래 기다리게 된다면, 손님은 다른 매장으로 갈 수도 있다.
- 오라클의 데이터 검색 과정:
- 위 예시에서 매장은 메모리(Database Buffer Cache), 창고는 하드디스크에 해당한다.
- 사용자가 데이터 요청을 하면, User Process가 메모리(Database Buffer Cache)에서 해당 데이터를 먼저 찾다.
- 만약 메모리에 데이터가 없다면, Server Process는 디스크에서 해당 데이터가 들어 있는 블록을 찾아 메모리로 복사해온다.
- 하드디스크에서 데이터를 찾아 복사하는 데 시간이 오래 걸리거나 블록 수가 많다면, User Process는 오랜 시간 동안 대기해야 한다.
Fetch 단계 (인출)
Execute 단계가 완료되면, 사용자가 요청한 데이터가 포함된 블록이 메모리(Database Buffer Cache)로 올라오게 된다. 하지만 여기서 중요한 점은 오라클의 I/O 최소 단위가 Block이라는 사실이다.
- Block 단위의 데이터 포함:
- Database Buffer Cache에는 사용자가 요청한 데이터만이 아닌, 해당 블록에 포함된 다른 데이터도 함께 들어 있다.
- 따라서, 사용자가 원하는 데이터만을 골라내는 추가 과정이 필요한데, 이 과정을 Fetch(인출)이라고 한다.
- 정렬 작업:
- 만약 사용자가 데이터 정렬(Sort) 등의 추가 작업을 요구했다면, Fetch 과정에서 정렬 작업이 수행된다.
- 정렬 작업은 PGA (Program Global Area)라는 메모리 공간에서 이루어지며, 각 서버 프로세스마다 독립적으로 할당되어 사용된다.
Update 문장의 실행 원리
오라클에서 SQL 문장은 기본적으로 동일한 수행 원리를 따른다. INSERT, UPDATE, DELETE, MERGE 문장 모두 비슷한 수행 과정을 거치지만, 여기서는 특히 UPDATE 문장이 수행되는 원리를 살펴보며 SGA(System Global Area)가 어떻게 활용되는지 알아보겠다.
UPDATE 문장은 SELECT 문과 유사한 수행 단계를 따르지만, Fetch 과정이 없다는 점이 다르다. 그러나 Execute 단계는 SELECT문보다 더 복잡하다.
예시 SQL 문장
UPDATE emp SET sal = 3000 WHERE empno = 70위와 같은 UPDATE 문장이 수행되었다고 가정하고, 오라클의 내부 작동 원리를 보면
- PARSE 단계:
- SELECT문과 마찬가지로, 서버 프로세스는 우선적으로 PARSE 단계를 거친다.
- 이 단계에서 문법 검사, 의미 검사, 권한 검사를 수행하여 문장의 유효성을 확인한다.
- 이후, Shared Pool 내 Library Cache를 살펴보면서 해당 SQL 문장과 실행 계획이 이미 존재하는지 확인한다. 이를 Soft Parse라고 한다.
- Hard Parse:
- 만약 Soft Parse가 실패한다면, 옵티마이저에게 새로운 실행 계획을 생성하도록 요청하게 된다.
- 옵티마이저는 복잡한 과정을 통해 새로운 실행 계획을 생성하며, 이 과정을 Hard Parse라고 한다.
UPDATE 문장의 수행 원리와 실행 계획
오라클에서 SQL 문장이 수행되는 원리.
- 실행 계획 생성:
- UPDATE 문장도 우선적으로 PARSE 과정을 거쳐 실행 계획을 생성하거나, 이미 존재하는 실행 계획을 Library Cache에서 가져온다.
- 실행 계획이 생성된 후 서버 프로세스는 다음 단계인 Execute를 수행하게 된다.
- Database Buffer Cache 확인:
- PARSE 단계가 끝나면, 서버 프로세스는 Database Buffer Cache를 확인하여, emp 테이블의 해당 데이터(예: empno = 7901)가 이미 있는지 확인한다.
- 만약 Database Buffer Cache에 해당 데이터가 없다면, 데이터 파일로 이동하여 해당 블록을 Database Buffer Cache로 복사해온다.
- 이 부분까지는 SELECT 문과 동일하게 진행된다.
- Execute 단계:
- Execute 단계에서 서버 프로세스는 변경될 데이터의 블록을 Database Buffer Cache로 가져온다.
- 이후, 데이터의 변경 내역을 Redo Log Buffer에 먼저 기록한다.
- Redo Log Buffer는 변경 내역을 저장하는 공간으로, 장애 발생 시 이를 복구하기 위한 정보가 저장된다.
- Undo Segment 기록:
- 변경된 데이터의 이전 값(원본 데이터)을 Undo Segment에 기록하여, 트랜잭션이 롤백될 경우 복구할 수 있게 한다.
- Database Buffer Cache 변경:
- Redo Log Buffer와 Undo Segment에 기록한 후, Database Buffer Cache의 데이터를 변경하게 된다.
이처럼 데이터 변경 과정은 다음과 같은 순서로 이루어진다:
- Redo Log Buffer 기록 ➔ Undo Segment 기록 ➔ Database Buffer Cache의 데이터 변경
오라클은 이 순서를 통해 트랜잭션(Transaction)의 데이터 일관성을 유지한다. 트랜잭션은 데이터의 변경 작업을 의미하며, 시스템 성능과 안정성에 중요한 영향을 미친다.
Oracle Server의 프로세스 구조
Oracle 서버는 다양한 프로세스 구조를 통해 운영 및 유지된다.
1. User Process (사용자 프로세스)
- 역할: 사용자가 Oracle 서버에 접속할 때 생성되는 프로세스로, 사용자로부터 SQL 문장 등의 요청을 받아 Server Process로 전달한다.
- 특징: 사용자가 접속을 종료하면 해당 User Process도 종료된다.
2. Server Process (서버 프로세스)
- 역할: User Process가 전달한 SQL 문장을 실제로 해석하고 실행하여 사용자 요청을 처리하는 프로세스이다.
- 특징: User Process와 마찬가지로, 사용자 접속과 함께 생성되고 접속이 종료되면 함께 종료된다.
3. Background Process (백그라운드 프로세스)
- 역할: Oracle Server가 시작될 때 자동으로 생성되며, 서버의 운영과 유지 관리를 담당하는 핵심 프로세스이다.
- 특징: User Process나 Server Process와 달리, 서버가 종료될 때까지 계속 유지된다.
Background Process는 다시 필수 프로세스와 선택적 프로세스로 나뉩니다:
- 필수 Background Process: Oracle 서버가 정상적으로 작동하기 위해 반드시 필요한 프로세스들이다.
- 선택적 Background Process: 특정 기능을 사용할 때에만 생성되는 프로세스이다.
필수 Background Process - DBWR (Database Writer)
DBWR(Database Writer) 프로세스는 Oracle 서버의 필수 백그라운드 프로세스 중 하나로, 데이터의 안정적인 저장을 보장하는 중요한 역할을 한다.
DBWR은 Database Buffer Cache에 있는 Dirty Block을 데이터 파일에 쓰는 작업을 담당한다. Oracle에서의 모든 데이터 변경 작업은 먼저 Database Buffer Cache에서 이루어지며, 이를 실제 데이터 파일로 내려 쓰지 않으면 데이터 손실이 발생할 수 있다. 이러한 변경 사항을 데이터 파일에 저장하여 영구적으로 기록하는 역할을 하는 프로세스가 바로 DBWR이다.
DBWR가 Database Buffer Cache의 Dirty Buffer를 파일로 내려 쓰는 경우
DBWR이 Database Buffer Cache의 변경된 내용을 데이터 파일로 저장하는 상황은 다음과 같다:
- Checkpoint 신호가 발생했을 때
- Dirty Buffer의 수가 임계값을 초과했을 때
- Time out이 발생했을 때
- RAC Ping이 발생했을 때
- Tablespace가 Read-only 상태로 변경될 때
- Tablespace가 offline 상태로 변경될 때
- Tablespace가 Begin Backup 상태가 될 때
- DROP TABLE 또는 TRUNCATE TABLE 문이 실행될 때
- Direct Path Read/Write 작업이 진행될 때
- 일부 Parallel Query 작업이 진행될 때
다중 DB Writer 프로세스
Oracle 서버는 성능 향상을 위해 하나 이상의 DB Writer 프로세스를 사용하도록 설정할 수 있다. DBWR0 ~ DBWR9 등 여러 DB Writer 프로세스를 동시에 사용할 수 있으며, 이를 통해 대용량 데이터 변경 작업을 효율적으로 처리할 수 있다. 다만, 단일 프로세서 시스템에서는 보통 하나의 DB Writer만 사용된다.
LGWR (Log Writer)의 역할
LGWR(Log Writer) 프로세스는 오라클 데이터베이스에서 중요한 역할을 한다. 데이터가 변경되면, 그 변경 내용은 메모리의 Redo Log Buffer에 기록되며, 이후 특정 조건에서 Redo Log File로 내려쓰기가 이루어진다.
LGWR가 Redo Log Buffer의 내용을 Redo Log File로 기록하는 조건:
- Commit 발생 시: 트랜잭션이 커밋될 때, 데이터 변경 내용이 Redo Log File에 기록된다.
- Redo Log Buffer가 1/3 가득 찼을 때: Buffer 사용량이 1/3을 넘으면 LGWR가 내용을 디스크에 기록한다.
- 변경된 데이터 양이 1MB에 도달했을 때: 1MB에 이르면 LGWR가 기록을 수행한다.
- 3초마다 주기적으로: LGWR는 주기적으로 3초마다 Redo Log Buffer를 파일로 내려 쓴다.
- DBMS 종료 전에: 데이터베이스가 정상적으로 종료되기 전, LGWR가 Buffer 내용을 모두 기록하여 데이터 보존을 보장한다.
이러한 저장 방식은 Redo Log Buffer가 메모리이기 때문에 전원 장애 등으로 서버가 꺼지면 데이터가 유실될 수 있기 때문이다. 하드디스크의 Redo Log File에 저장해 안전하게 변경 기록을 보존하는 것이다.
Redo Log의 특징: Write-Ahead Logging
오라클은 Log-Ahead Method (Write-Ahead Logging)을 사용하여, 데이터 변경 시 Redo Log Buffer에 변경 내역을 먼저 기록하고, 이후 Database Buffer Cache의 내용을 수정한다. 이로 인해 장애가 발생하더라도, Redo Log File에 저장된 변경 내역을 통해 데이터 복구가 가능한다.
많이 발생하는 오해 중 하나는, Commit이 데이터 파일로 데이터를 저장한다는 잘못된 이해이다. 실제로 Commit은 Redo Log Buffer의 내용을 Redo Log File에 저장하는 것이며, 데이터 파일에 기록되는 것은 아니다.
Commit 시 Redo Log Buffer에 먼저 기록하는 이유
Commit 시에 Database Buffer Cache의 내용이 아닌 Redo Log Buffer의 내용을 먼저 저장하는 이유는 성능 최적화와 데이터 일관성을 보장하기 위해서이다.
- 쓰기 속도 향상
- Database Buffer Cache의 블록 크기는 기본적으로 8KB(1GB 환경 기준)이다. 데이터가 일부만 변경되더라도, 전체 블록을 다시 써야 하므로 쓰기 작업이 비교적 느리다.
- 반면, Redo Log Buffer의 블록 크기는 512 bytes로 작기 때문에 상대적으로 빠르게 기록이 가능하여 저장 시간을 단축하고 성능을 높이는 데 유리하다.
- 기록 방식 차이
- Database Buffer Cache의 내용을 데이터 파일에 쓸 때는 원래 위치를 찾아 덮어쓰는 방식이므로 시간이 오래 걸릴 수 있다.
- 반대로 Redo Log File에 쓰는 방식은 순차적으로 기록하는 방식이라 훨씬 빠르게 작업이 완료된다. 이 방식은 Write-Ahead Logging의 일환으로, 데이터 손실을 방지하면서 성능을 최적화하는 데 도움을 준다.
- Group Commit 기법으로 효율성 증대
- 여러 사용자가 동시에 Commit을 요청하면, LGWR(Log Writer)은 이 요청들을 모아서 한 번에 Redo Log File에 기록한다. 이 방식은 Group Commit이라 불리며, disk I/O 작업을 줄이고 전체 성능을 높이는 역할을 한다.
- Redo Log File의 가용성 문제
- 만약 Commit 요청 시 Redo Log File이 없는 상황이라면, LGWR은 에러 내용을 Alert log 파일에 기록하고, 이후 Commit 요청을 수행하지 않고 대기한다. 이는 데이터 손실을 방지하기 위한 안전 장치이다.
PMON (Process Monitor)의 역할
PMON은 Oracle Database의 Process Monitor로서, 데이터베이스의 모든 서버 프로세스를 감시하고 비정상적으로 종료된 프로세스를 감지하며 복구 작업을 수행한다.
- 비정상 종료된 프로세스 복구
- 서버 프로세스가 비정상적으로 종료되면, 해당 프로세스가 사용하던 자원(메모리, 트랜잭션, 락 등)을 해제한다.
- 종료된 프로세스가 Transaction ID와 같은 중요한 정보를 사용하고 있었다면, PMON이 이를 정리하여 시스템의 일관성을 유지하도록 돕는다.
- Listener 등록 및 관리
- 인스턴스가 시작될 때, 해당 인스턴스 정보를 Listener에 등록하여 클라이언트가 데이터베이스에 연결할 수 있도록 한다.
- Listener는 클라이언트 연결을 데이터베이스와 연결하는 네트워크 인터페이스 역할을 하며, PMON은 이를 통해 데이터베이스 인스턴스가 외부에서 접속 가능하도록 관리한다.
SMON (System Monitor)의 역할
SMON은 Oracle Database의 System Monitor로, 데이터베이스 인스턴스가 정상적으로 유지되도록 다양한 복구 및 관리 작업을 수행한다.
- 인스턴스 복구 (Instance Recovery)
- 인스턴스가 비정상적으로 종료되었을 경우, 인스턴스를 다시 시작하면서 Instance Recovery를 수행하여 데이터베이스의 일관성을 회복한다.
- Instance Recovery는 트랜잭션 복구를 통해 미완료된 트랜잭션을 롤백하고, 커밋된 변경사항을 보장하여 데이터 무결성을 유지한다.
- Temporary Segment 정리
- 인덱스 생성과 같은 작업 중 사용되는 Temporary Segment를 관리한다. 만약 작업 중 세션이 비정상 종료되면 SMON이 임시 세그먼트를 정리하여 공간을 확보한다.
- Free Extents 정리
- Dictionary 관리 방식을 사용하는 경우, 사용되지 않는 Free Extents를 정리하여 테이블 스페이스의 저장 공간을 효율적으로 관리한다.
예제 상황에서의 SMON 역할
가정 상황:
- 사용자가 A 데이터를 입력한다.
- 사용자가 B 데이터를 입력한다.
- 커밋을 수행한다.
- C 데이터를 입력한다.
만약 이 상태에서 인스턴스가 비정상 종료되었다면, SMON이 인스턴스 복구를 시작하며 다음과 같은 작업을 수행한다:
- 커밋된 데이터 A와 B를 보장하고,
- 커밋되지 않은 C 데이터를 롤백하여 일관성을 회복한다.
Oracle Database가 비정상적으로 종료되었다가 재시작될 때 수행되는 Instance Recovery의 절차는 Online Redo Log 파일에 기록된 정보를 이용해 데이터베이스를 일관성 있게 복구한다.
Instance Recovery 절차
- Parameter File 읽기 및 NOMOUNT 단계
- 시스템 파라미터 파일을 읽어 NOMOUNT 단계에서 인스턴스를 생성한다.
- MOUNT 단계에서 Control File 확인
- MOUNT 단계로 진행하여 Control File을 확인하고, 이 파일에서 인스턴스가 정상적으로 종료되지 않았음을 확인한다. 이를 통해 Instance Crash 상황을 인지한다.
- Redo Log File을 통한 Roll Forward 작업
- Redo Log File에서 커밋된 트랜잭션과 미처리된 변경사항들을 재적용한다. 이 과정을 Roll Forward라고 하며, 최근에 커밋된 내용과 커밋되지 않은 변경 사항이 모두 포함된다.
- 주의할 점은, 커밋되지 않은 변경사항(예: 작업 4번)도 이 단계에서 메모리에 반영된다는 것이다.
- Database Open
- 데이터베이스를 Open하여, 일반적인 사용이 가능하도록 한다.
- Roll Backward로 커밋되지 않은 트랜잭션 취소
- 커밋되지 않은 변경 사항을 롤백하여 원래 상태로 되돌린다. 이 과정을 Roll Backward라고 하며, 커밋이 안 된 작업 4번이 이 단계에서 취소된다.
추가 주의 사항
- Instance Recovery는 Online Redo Log File만을 이용한다.
- 만약 복구해야 할 내용이 Archived Redo Log File에 포함되어 있다면, Instance Recovery로는 복구되지 않으며 DBA가 Media Recovery를 수동으로 수행해야 한다.
주요 Oracle 백그라운드 프로세스
- CKPT (Checkpoint Process)
- Checkpoint는 Oracle이 데이터베이스의 현재 상태를 기록하여, 장애 발생 시 빠른 복구를 돕는 중요한 작업이다.
- CKPT 프로세스는 DBWR 프로세스에 Checkpoint 신호를 보내며, Control File과 Data File Header에 현재의 Checkpoint 정보를 기록한다.
- 이 정보는 Checkpoint 위치, SCN (System Change Number), 그리고 해당 내용을 포함한 Redo Log의 위치 등의 필수 정보로 구성된다.
- MMON 및 MMNL (Manageability Monitor Processes)
- MMON (Manageability Monitor) 프로세스는 AWR (Automatic Workload Repository)와 관련된 다양한 작업을 수행한다. AWR은 성능 데이터와 진단 정보를 주기적으로 수집하여 데이터베이스 상태를 모니터링하고 관리하는 데 사용된다.
- MMNL (Memory Monitor Light) 프로세스는 ASH (Active Session History) 데이터를 디스크에 기록하는 역할을 하며, 이는 세션 성능 분석에 유용한 정보를 제공한다.
- RECO (Recoverer Process)
- RECO는 분산 데이터베이스 환경에서 2-Phase Commit을 사용하는 트랜잭션 복구를 담당하는 프로세스이다.
- 트랜잭션 중 장애가 발생하면 자동으로 복구 작업을 수행한다. 단일 데이터베이스 환경에서는 크게 사용되지 않으며, 주로 분산 환경에서 중요하게 작동한다.
선택적인 백그라운드 프로세스
- ARCn (Archiver Processes)
- ARCn 프로세스는 데이터베이스가 Archive Log Mode로 운영될 때 활성화된다.
- 이 프로세스는 Redo Log File의 변경 내용을 Archive Log로 저장해, 데이터 복구와 백업 작업에 중요한 역할을 한다. Archive Log Mode가 아니라면 이 프로세스는 동작하지 않다.
- CJQ0 및 Jnnn (Job Queue Processes)
- CJQ0는 Oracle Job 기능을 수행하는 프로세스이며, 이 기능은 미리 정의된 작업을 예약된 시간에 자동으로 실행한다.
- 이는 유닉스의 Cron 기능과 비슷하게 특정 시간에 작업을 수행하도록 설정할 수 있는 기능이다. , 주기적인 데이터 백업이나 시스템 모니터링 작업을 예약할 때 유용하다.
- FBDA (FlashBack Data Archiver Process)
- FBDA 프로세스는 Oracle 11g 버전부터 도입된 Flashback Data Archive 기능을 지원한다.
- Flashback 기능 중 일부는 Undo Data를 사용하여 데이터 복구를 지원하는데, 기존에는 Undo Data가 다른 트랜잭션에 의해 덮어씌워지면 Flashback이 불가능한 한계가 있었다.
- FBDA는 Undo Data를 아카이빙하여, 다른 사용자가 덮어쓰기 전에 데이터를 안전하게 보관해준다. 이를 통해 Undo Data가 유실되지 않도록 하여, Flashback 복구 기능을 안정적으로 수행할 수 있게 한다.
Oracle 서버 시작 방법
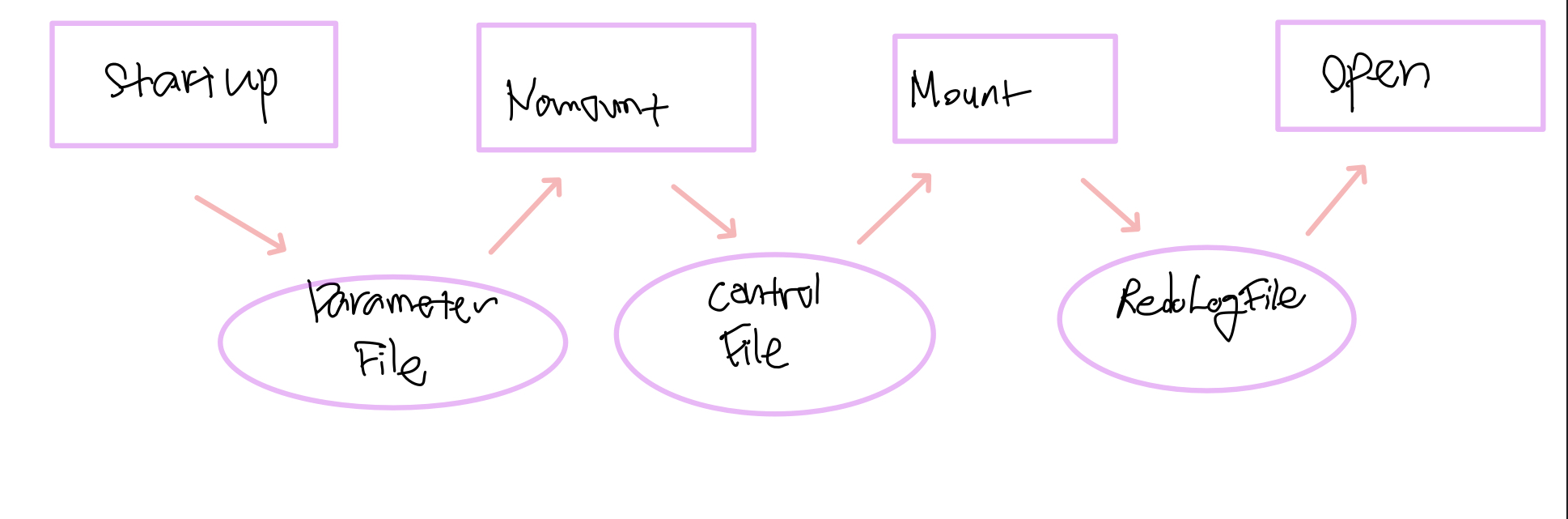
Oracle Database를 시작하여 데이터베이스에 접근하려면 서버 인스턴스가 OPEN 상태에 있어야 한다.
- NOMOUNT 단계
- 인스턴스를 시작할 때 가장 먼저 Parameter File을 읽는다. 이 파일에는 서버 인스턴스에 필요한 여러 파라미터 값들이 포함되어 있다.
- Parameter File에는 정적 Parameter File(PFILE)과 동적 Parameter File(SPFILE)이 있으며, 정적 파일은 수동으로만 수정 가능하고, 동적 파일은 Oracle 서버에서 자동으로 관리된다.
- NOMOUNT 단계에서는 Parameter File의 내용을 참조하여 인스턴스(SGA와 Background Process들)가 메모리에 생성된다. 이후 Alert Log 파일이 열려 로깅을 시작한다.
- Alert Log 파일은 인스턴스의 운영 상태 및 각종 오류나 경고 메시지를 기록하는 매우 중요한 로그 파일로, 서버에서 문제 발생 시 확인이 필요한다.
- Alert Log 파일 위치
- Oracle 10g: $ORACLE_BASE/admin/SID/bdump/alert_SID.log
- Oracle 11g 이후: $ORACLE_BASE/diag/rdbms/SID/SID/trace/alert_SID.log
- MOUNT 단계
- Control File을 읽어 데이터베이스의 구조와 Redo Log 파일의 위치를 확인한다.
- 이 단계에서는 데이터베이스가 열리지 않았기 때문에 데이터에 접근할 수는 없지만, Control File을 통해 데이터베이스의 구조를 파악할 수 있다.
- OPEN 단계
- 이 단계에서 Data File과 Redo Log File을 열어 사용자들이 데이터베이스에 접근할 수 있도록 한다.
- 데이터베이스가 완전히 열린 상태에서는 데이터 조회, 입력, 수정 등의 작업을 수행할 수 있다.
실시간 로그 확인
유닉스 환경에서 Alert Log 파일의 실시간 업데이트를 확인
tail -f <Alert Log 파일 경로>이 명령어를 통해 인스턴스 시작과정에서 발생하는 메시지나 에러 로그를 실시간으로 모니터링할 수 있다.
MOUNT 단계와 Control File
- MOUNT 단계
MOUNT 단계에서는 Control File을 읽어 Database의 구조와 이상 유무를 확인한다. Control File에는 데이터베이스 전체의 상태 정보가 저장되어 있으며, Parameter File에 위치가 기록되어 있다. - 이 단계에서 데이터베이스의 이상 유무를 확인하여 문제가 없으면 OPEN 단계로 진입하게 된다. 반면, 데이터베이스가 비정상 종료(예: 정전)되어 Instance Crash로 판단될 경우, OPEN 단계로 가기 전에 Instance Recovery가 필요할 수 있다.
- Instance Recovery
Instance Recovery는 SMON 프로세스에 의해 수행된다. SMON은 복구 작업에 필요한 변경 내역을 Redo Log File에서 찾다. 만약 Redo Log File에 복구해야 할 정보가 없고, Archived Log File에 있다면 Instance Recovery는 자동으로 수행되지 않으며, DBA가 수동으로 Media Recovery를 수행해야 한다.
인스턴스를 시작할 때 가장 먼저 사용하는 Parameter File에 은 NOMOUNT 단계에서 인스턴스를 설정하고 구성하는 데 중요한 역할을 한다.
Parameter File(초기화 파라미터 파일)
1. 파라미터란?
Oracle Database의 파라미터는 데이터베이스 설정을 관리하는 데 사용되는 변수와 비슷한다. Oracle이 데이터베이스를 어떻게 운영할지에 대한 설정 값을 정의하는 역할을 하며, 두 가지 유형이 있다:
- 묵시적 파라미터 값: 관리자가 명시적으로 설정하지 않아도 Oracle이 자동으로 기본값을 적용하는 파라미터.
- 명시적 파라미터 값: 관리자가 직접 설정해야 값이 정해지는 파라미터.
이러한 파라미터들을 하나로 모아 구성한 파일이 파라미터 파일(Parameter File)이다. 파라미터 파일은 데이터베이스 인스턴스 시작 시 메모리 할당, SGA 생성, 그리고 Background Process들을 실행하기 위해 Oracle 커널이 참조하는 중요한 설정 파일이다. 이 파일에는 두 가지 형태가 있다:
- Pfile (정적 파라미터 파일)
- Spfile (동적 파라미터 파일)
2. Pfile과 Spfile 비교
| 파일 위치 | $ORACLE_HOME/dbs (공통) | $ORACLE_HOME/dbs (공통) |
| 파일 이름 | initSID.ora | spfileSID.ora |
| 내용 변경 | 관리자가 수동으로 변경 | 서버 프로세스가 자동으로 변경 |
| 파일 형태 | 텍스트 파일 (OS 편집기 사용 가능) | 바이너리 파일 (OS 편집기 사용 불가) |
주요 특징 요약
- Pfile: 텍스트 형식의 파일로, 관리자가 직접 열어 수정할 수 있다.
- Spfile: 바이너리 형식의 파일로, Oracle 서버 프로세스가 직접 읽고 수정하며, OS 편집기를 통해 수정할 수 없다.
Pfile과 Spfile의 중요성 및 차이점
Oracle Database에서 Pfile과 Spfile은 Oracle Server가 성공적으로 시작되기 위해 반드시 필요한 파일이다.
1. 파일 경로와 이름
- Pfile과 Spfile은 정해진 디렉토리에 정해진 이름으로 존재해야 하며, Oracle Server가 STARTUP 명령을 실행할 때 이를 찾을 수 있어야 한다.
- 파일이름에 포함된 SID(System Identifier)는 각 데이터베이스 인스턴스를 식별하는 데 사용되며, 동일한 시스템에서 여러 데이터베이스를 관리할 때 구분 역할을 한다.
- , 데이터베이스 이름이 test일 경우:
- Pfile의 이름: inittest.ora
- Spfile의 이름: spfiletest.ora
2. 파일 형식과 편집 방법
- Pfile:
- 형태: 텍스트 파일로 구성되어 있다.
- 편집: OS 편집기(예: 메모장, Vi 편집기 등)를 사용하여 관리자가 직접 내용을 수정할 수 있다.
- Spfile:
- 형태: 바이너리 파일로 되어 있다.
- 편집: 일반적인 텍스트 편집기에서는 내용을 수정할 수 없으며, 변경이 필요한 경우 DB 사용자가 SQL 명령을 통해 설정을 조정하면, Oracle 서버 프로세스가 자동으로 해당 파일을 수정한다.
3. 파일의 중요성
- Oracle Server 시작: Pfile과 Spfile이 올바른 경로와 이름으로 존재해야만 Oracle Server가 시작될 수 있으며, 파일을 찾을 수 없으면 오류가 발생한다.
- DB 인스턴스의 설정: 이 파일들은 Oracle 인스턴스의 메모리 구조 및 동작 방식을 정의하며, 각종 성능 및 안정성을 조정하는 데 필요한 필수적인 요소이다.
Oracle Database는 8i 버전까지 Pfile을 기본 파라미터 파일로 사용하였으나, 9i 버전부터는 Spfile이 기본 파라미터 파일로 채택되었다. 그러나 9i 이후 버전에서도 여전히 Pfile을 사용할 수 있으며, 11g 버전에서도 Pfile의 사용이 계속되고 있다. 이 두 가지 파일을 잘 이해하는 것은 Oracle Database의 관리와 운영에 매우 중요한다.
Spfile과 Pfile의 변화
- Spfile의 도입 (9i 버전)
- Spfile이 도입됨으로써 Oracle Database는 자동 튜닝 기능을 지원하게 되었다.
- Spfile은 서버 프로세스가 직접 내용을 변경할 수 있는 형태로, Oracle이 성능을 최적화하기 위해 필요한 파라미터를 동적으로 조정할 수 있도록 한다.
- 이로 인해 수동으로 파라미터를 조정해야 했던 이전 버전들과는 달리, Spfile을 사용하면 Oracle이 시스템 상태에 따라 적절한 설정을 자동으로 관리할 수 있다.
- Pfile의 계속된 사용
- Pfile은 여전히 유용하게 사용될 수 있으며, 관리자가 직접 텍스트 편집기를 통해 수정할 수 있기 때문에 특정 상황에서 더 직관적일 수 있다.
- Pfile은 주로 테스트 환경이나 간단한 구성에서 사용되며, Oracle Database의 초기 설정 및 문제 해결 시 유용하다.
Oracle Database 9i 이후 버전에서는 Spfile이 기본 파라미터 파일로 설정되며, Pfile은 필요할 경우 수동으로 생성해야 한다.
Spfile과 Pfile의 특징
- Spfile (Server Parameter File)
- 형태: Spfile은 바이너리 파일로, 사용자가 직접 내용을 수정할 수 없다. 대신, Oracle Database가 이 파일의 내용을 자동으로 관리한다.
- 기본 경로: Spfile은 기본적으로 $ORACLE_HOME/dbs/spfile<SID>.ora 경로에 저장된다.
- 자동화: Spfile은 Oracle이 자동으로 파라미터 값을 조정하여 성능을 최적화할 수 있도록 지원한다.
- Pfile (Parameter File)
- 형태: Pfile은 텍스트 파일로, 사용자가 OS 편집기를 통해 내용을 직접 수정할 수 있다.
- 기본 경로: Pfile은 기본적으로 $ORACLE_HOME/dbs/init<SID>.ora 경로에 저장된다.
- 수동 관리: Pfile은 사용자가 직접 수정해야 하며, 데이터베이스 시작 시 필요한 파라미터를 설정하는 데 사용된다.
Spfile과 Pfile 생성 및 관리
- Spfile에서 Pfile 생성
- Spfile에서 Pfile을 생성하는 방법
CREATE PFILE FROM SPFILE; - 이 명령을 실행하면 현재 Spfile의 내용을 바탕으로 Pfile이 생성된다.
- Spfile에서 Pfile을 생성하는 방법
- Pfile에서 Spfile 생성
- 반대로 Pfile에서 Spfile을 생성하는 방법
CREATE SPFILE FROM PFILE;
- 반대로 Pfile에서 Spfile을 생성하는 방법
주의사항
- Spfile의 내용을 직접 수정하면 안 되며, 반드시 Oracle Database 프로세스를 통해 관리해야 한다.
- Pfile을 사용할 경우, 파라미터 값을 직접 수정할 수 있지만, 변경 후에는 데이터베이스를 다시 시작해야 적용된다.
Oracle Database에서 Pfile과 Spfile이 동시에 존재할 경우, 데이터베이스는 기본적으로 Spfile의 내용을 우선적으로 사용한다. 이는 Spfile이 Oracle Database의 자동화된 관리와 성능 조정을 지원하기 때문에, 관리자는 Pfile보다 Spfile을 사용하는 것이 일반적이다.
Spfile과 Pfile의 우선순위
- Spfile 존재 시:
- 데이터베이스를 시작할 때 Spfile이 존재하면, Oracle은 해당 파일의 파라미터 값을 읽어들여 데이터베이스의 설정을 구성한다.
- 이때 Pfile이 존재하더라도 Spfile의 내용이 우선적으로 적용된다.
- Pfile 존재 시:
- 만약 Spfile이 존재하지 않고 Pfile만 존재할 경우, Oracle은 Pfile을 사용하여 파라미터를 설정한다.
- Pfile은 수동으로 수정해야 하며, 수정한 내용을 적용하려면 데이터베이스를 재시작해야 한다.
예시
- Pfile과 Spfile 모두 존재할 때:
- spfiletestdb.ora가 존재하고, inittestdb.ora도 존재하는 경우, Oracle Database는 spfiletestdb.ora의 설정을 사용한다.
- Spfile이 없을 때:
- spfiletestdb.ora가 삭제되고 inittestdb.ora만 존재하는 경우, Oracle Database는 inittestdb.ora를 사용하여 데이터베이스를 시작한다.
관리 팁
- Spfile을 기본으로 사용:
- 관리자는 가능한 한 Spfile을 사용하여 파라미터를 관리하는 것이 좋다. 이렇게 하면 Oracle이 자동으로 성능을 조정할 수 있으며, 운영의 편리함을 더할 수 있다.
- Pfile 사용 시 주의사항:
- Pfile을 사용할 경우, 수동으로 수정하고 재시작해야 하는 번거로움이 있으므로, 필요한 경우에만 사용하는 것이 좋다.
Pfile의 변경
- 수동 변경:
- Pfile(initSID.ora)은 텍스트 파일이므로, 관리자(root 권한)가 메모장, vi 에디터 등을 사용하여 파일을 직접 수정할 수 있다.
- 변경된 사항은 데이터베이스를 재시작할 때 적용된다.
- 적용 시점:
- Pfile의 내용을 수정 후 저장하면, 수정된 내용은 다음에 데이터베이스를 시작할 때 반영된다. Pfile을 사용하면 변경 사항이 실시간으로 반영되지 않으며, 재부팅을 해야 적용된다.
Spfile의 변경
- ALTER SYSTEM SET 명령:
- Spfile(spfileSID.ora)은 바이너리 파일로, 직접 편집이 불가능하며 Oracle의 ALTER SYSTEM SET 명령을 통해 변경한다.
- Oracle은 ALTER SYSTEM SET을 통해 Spfile의 내용을 실시간으로 변경할 수 있으며, 일부 파라미터에 대해서는 재부팅 없이 즉시 적용할 수 있다.
- SCOPE 옵션:
- ALTER SYSTEM SET 명령에는 SCOPE 옵션을 통해 변경 사항의 적용 범위를 지정할 수 있다.
- SCOPE의 값은 다음과 같다:
- MEMORY: 변경 사항을 Spfile에 기록하지 않고, 현재 실행 중인 인스턴스에만 일시적으로 적용한다. 데이터베이스 재시작 시 원래 값으로 복원된다.
- SPFILE: 현재 인스턴스에는 적용하지 않고, Spfile에만 기록한다. 재부팅 후에 적용된다.
- BOTH: 현재 인스턴스와 Spfile 모두에 적용한다. 즉시 변경되며, 재부팅 후에도 적용된다. 기본값으로 SCOPE 옵션을 생략하면 BOTH로 적용된다.
예시: DB Cache Size 변경
ALTER SYSTEM SET db_cache_size=30M SCOPE=MEMORY;- 위 명령은 현재 인스턴스에만 DB Cache Size를 30MB로 설정하며, Spfile에는 기록하지 않으므로 데이터베이스를 재시작하면 원래 값으로 돌아간다.
주의사항
- Spfile은 성능이 뛰어나고, 재부팅 없이도 많은 파라미터를 실시간으로 변경할 수 있지만, 기존 Pfile 방식에 익숙한 사용자에게는 다소 불편할 수 있다.
- 특히 중요한 설정 변경 시에는 SCOPE 옵션을 신중히 선택하여 원하는 적용 범위를 명확히 지정해야 한다.
주요 파라미터 설정
BACKGROUND_DUMP_DEST
- 설명: 모든 백그라운드 프로세스의 로그 파일이 저장되는 경로를 지정하는 파라미터이다.
- 용도: 데이터베이스에서 발생하는 이벤트 및 오류 로그를 확인할 때 이 경로에서 로그 파일을 찾을 수 있다.
CLIENT_RESULT_CACHE_LAG (11g부터 사용 가능)
- 설명: 클라이언트 측에서 캐시된 결과의 유효 기간을 밀리초 단위로 설정한다.
- 용도: 클라이언트 캐시된 데이터의 최신 상태를 서버와 동기화하기 위한 대기 시간을 설정한다. 지정된 시간 동안 클라이언트가 캐시된 데이터를 사용하며, 이후에 서버에서 업데이트된 데이터를 가져온다.
CLIENT_RESULT_CACHE_SIZE (11g부터 사용 가능)
- 설명: 클라이언트 결과 캐시의 크기를 지정하는 파라미터로, 단위는 바이트이다.
- 용도: 클라이언트 측에서 캐싱할 수 있는 결과 데이터의 최대 크기를 설정하여 클라이언트 성능을 최적화한다.
CLUSTER_DATABASE
- 설명: Real Application Cluster(RAC) 환경에서만 사용하는 파라미터로, RAC를 사용할지 여부를 설정한다.
- 값: TRUE 또는 FALSE이며, 기본값은 FALSE이다.
- 용도: RAC 환경에서 다중 인스턴스가 데이터베이스에 접근하도록 설정할 때 TRUE로 설정한다. RAC 환경이 아닌 경우 기본적으로 FALSE로 설정되어 있다.
COMPATIBLE
- 설명: 하위 호환성을 위한 파라미터로, 데이터베이스의 호환 가능한 이전 버전을 지정한다.
- 기본값: Oracle 11g는 10.2.0이며, Oracle 10g는 10.0.0이다.
- 용도: 데이터베이스를 최신 버전으로 업그레이드해도, 지정된 호환성 버전과 호환되도록 설정할 수 있다. 호환성 문제 없이 이전 버전과의 데이터베이스 구조와 기능을 지원한다.
● CONTROL FILES
Control Files의 경로를 지정하는 파라미터이다. 최대 8개까지의 파일 이름을 등록할 수 있다.
● CURSOR_SHARING
CURSOR_SHARING은 하드 파싱을 줄이고 커서를 공유하기 위한 파라미터이다. 9i 이전 오라클에서는 동일한 SQL 문장을 작성해야만 커서가 공유되었는데, 바인드 변수를 사용한 경우에는 동일한 문장으로 인식되지 않아 재파싱이 자주 발생했다. 이를 해결하기 위해 등장한 파라미터로, 세 가지 모드가 있다.
- EXACT: 모든 문장과 변수 값이 동일해야 동일한 SQL로 인식한다. 기본값이다.
- SIMILAR: 문장이 동일하고 바인드 변수 값만 다를 경우에도 동일한 SQL로 인식한다.
- FORCE: 문장은 동일하나 상수 값이 다른 SQL일 경우에도 동일한 SQL로 인식한다.
이 파라미터는 Library Cache의 경합을 줄이기 위해 자주 사용되지만, 다양한 이슈가 발생할 수 있으므로 기본값을 유지하거나 충분한 테스트 후 변경하는 것을 권장한다.
● DB_BLOCK_SIZE
데이터베이스에서 사용될 기본 Block Size를 지정하는 파라미터이다. 일반적으로 4096(4K) 바이트나 8192(8K) 바이트를 사용하며, 데이터베이스를 생성할 때만 지정할 수 있다. 이 값은 한 번 지정되면 데이터베이스 재생성 전까지는 변경할 수 없다. 9i 버전까지 기본값은 4KB였으나, 10g 이후 버전부터 기본값이 8KB로 변경되었다.
● DB_CACHE_ADVICE
DB_CACHE_ADVICE는 V$DB_CACHE_ADVICE 뷰에서 다양한 캐시 사이즈와 관련된 정보를 수집할지 여부를 결정하는 파라미터이다. 주로 데이터베이스 성능을 조정할 때 유용하며, 이 파라미터에는 두 가지 주요 값이 있다:
- OFF: 기능을 사용하지 않으며 메모리도 할당되지 않는다.
- ON: 기능을 사용하여 추가적인 캐시 사이즈 정보를 수집한다. 이 옵션을 사용하면 추가적인 메모리 사용이 발생할 수 있으므로 성능 테스트 등을 위해 일시적으로 사용하는 것이 좋다.
참고: OFF에서 ON으로 변경할 경우 에러가 발생할 수 있으므로 적절히 설정하여 사용해야 한다.
● DB_CACHE_SIZE
DB_CACHE_SIZE는 Default Database Buffer Cache의 크기를 결정하는 파라미터이다. 데이터 변경이나 조회 시 필수적으로 활용되는 기본 캐시이다.
이 파라미터에 “Default”라는 이름이 붙은 이유는 DB_KEEP_CACHE_SIZE, DB_RECYCLE_CACHE_SIZE 같은 추가 캐시 파라미터가 존재하기 때문이다. DB Cache는 DB_BLOCK_SIZE에서 지정된 Block 크기를 사용해 생성된다.
● DB_CREATE_FILE_DEST
DB_CREATE_FILE_DEST는 Oracle Managed Files (OMF) 환경에서 데이터 파일이 생성될 위치를 지정하는 파라미터이다. 오라클이 데이터베이스 파일 (Data file, Redo log file, Control file 등)을 관리하는 방식은 크게 두 가지로 구분된다.
- User Managed File (UMF): 관리자가 직접 파일의 위치와 이름을 지정하고 관리하는 방식이다.
- Oracle Managed File (OMF): 오라클이 파일의 위치 및 이름을 자동으로 관리하는 방식으로, 9i 버전부터 사용 가능한다.
OMF를 사용할 경우, 사용자가 파일 경로만 지정하면 오라클이 자동으로 관리하므로 파일 관리를 쉽게 할 수 있다.
● DB_CREATE_ONLINE_LOG_DEST_n
DB_CREATE_ONLINE_LOG_DEST_n는 Oracle Managed Files (OMF) 환경에서 Redo Log File과 Control File의 생성 위치를 지정하는 파라미터이다. 안정적인 운영을 위해 여러 경로에 다중화 설정을 하는 것이 권장되며, 파라미터 이름의 마지막 부분 n은 숫자로 지정할 수 있다. n은 최대 5까지 지정할 수 있으며, 이는 최대 5곳까지 Redo Log File과 Control File의 다중화를 지원한다는 의미이다.
● DB_DOMAIN
DB_DOMAIN는 물리적으로 서로 다른 네트워크에 있는 오라클 인스턴스들을 하나의 논리적 그룹으로 묶어주는 파라미터이다. 도메인은 물리적으로 떨어져 있어도 논리적으로 하나의 단위로 연결된 집합을 의미한다. , 서울과 부산에 각각 위치한 오라클 대학교 캠퍼스가 물리적으로 떨어져 있지만, 동일한 도메인으로 묶여 하나의 논리적 그룹으로 설정될 수 있다.
● DB_FILE_MULTIBLOCK_READ_COUNT
DB_FILE_MULTIBLOCK_READ_COUNT는 Index Scan이 아닌 Full Scan이나 Index Full Scan을 수행할 때, 하드디스크의 데이터 파일에서 Database Buffer Cache로 한 번에 가져올 수 있는 블록의 개수를 지정하는 파라미터이다.
이 값은 운영 체제에 따라 달라지며, 일반적으로 OLTP 시스템의 경우 4에서 32 사이의 값을 가진다. 이 파라미터는 주로 데이터베이스 튜닝에서 중요한 역할을 하며, 설정한 값만큼 데이터를 한 번에 메모리로 로드하므로 디스크 I/O 횟수를 줄일 수 있다.
주의: 이 파라미터 값을 높인다고 해서 무조건 성능이 향상되는 것은 아니다.
●DB_KEEP_CACHE_SIZE
DB_KEEP_CACHE_SIZE는 Keep Buffer Cache의 크기를 지정하는 파라미터이다. 이 영역은 LRU 알고리즘의 영향을 받지 않고 데이터를 계속 유지하는 역할을 한다. 특정 데이터를 자주 사용하는 경우, 이 공간을 사용하여 성능을 향상시킬 수 있다.
● DB_NAME
DB_NAME은 데이터베이스의 이름을 지정하는 파라미터로, Single 환경에서는 인스턴스 이름과 데이터베이스 이름을 동일하게 사용할 수 있다. RAC 환경에서는 인스턴스 이름과 데이터베이스 이름이 다를 수 있다. 이 이름은 최대 8자까지 설정 가능하며, 대소문자를 구분하지 않다.
● DB_nK_CACHE_SIZE
DB_nK_CACHE_SIZE는 Database Buffer Cache를 생성할 때 비표준 블록 크기로 생성하는 크기를 지정하는 파라미터이다. , 기본 블록 크기가 8K인데, 4K 블록 크기를 가진 테이블스페이스를 생성하려면, DB_4K_CACHE_SIZE 값으로 Database Buffer Cache를 생성해줘야 한다.
● DB_RECOVERY_FILE_DEST
DB_RECOVERY_FILE_DEST는 Flash Recovery Area의 경로를 지정하는 파라미터이다. 이 영역은 RMAN 백업 파일과 Flashback log 파일, 그리고 Archived Redo Log 파일이 저장되는 위치이다. 11g 버전부터는 이 공간이 Fast Recovery Area로 명명되었다.
● DB_RECOVERY_FILE_DEST_SIZE
DB_RECOVERY_FILE_DEST_SIZE는 Flash Recovery Area의 크기를 지정하는 파라미터이다. 기본값은 10g에서 2GB, 11g에서 4GB로 설정된다.
● DB_UNIQUE_NAME
DB_UNIQUE_NAME은 데이터베이스의 유일한 이름을 지정하는 파라미터이다. Data Guard 환경에서 Physical Standby Database의 경우, 원본 데이터베이스와 DB_NAME이 동일하지만, DB_UNIQUE_NAME은 달라야 한다. 회사 내에서 이 이름은 반드시 유일해야 한다. 기본적으로 Instance 환경에서는 DB_NAME, ASM 인스턴스 환경에서는 +ASM으로 설정된다.
● DB_WRITER_PROCESSES
DB_WRITER_PROCESSES는 백그라운드 프로세스 중 하나인 Database Writer (DBWR) 프로세스의 개수를 지정하는 파라미터이다. 일반적으로 1 또는 CPU 개수/8 중 더 큰 값을 사용한다.
위의 파라미터들은 Oracle Database의 성능 및 관리 효율성을 극대화하는 데 중요한 역할을 한다. 설정값을 변경하기 전에 항상 테스트를 통해 충분한 검증을 진행한 후 적용하는 것이 좋다.
● INSTANCE_NUMBER
INSTANCE_NUMBER는 RAC 환경에서 인스턴스의 고유한 번호를 지정하는 파라미터이다. 이 파라미터를 통해 RAC의 각 인스턴스가 고유의 식별번호를 가지며, 인스턴스 번호는 기본적으로 1부터 최대 255까지 설정할 수 있다.
● LDAP_DIRECTORY_SYSAUTH
LDAP_DIRECTORY_SYSAUTH는 SYSDBA나 SYSOPER 권한의 인증을 디렉토리 서비스를 통해 가능하게 하는 파라미터이다. YES와 NO 값을 가지며, 기본값은 NO이다. YES로 설정 시 LDAP 디렉토리 인증 기능이 활성화된다.
● LOG_ARCHIVE_DEST_n
LOG_ARCHIVE_DEST_n는 로그 아카이브 위치를 지정하는 파라미터이다. 특정 위치를 지정하지 않을 경우 Flash Recovery Area에 Redo Log가 저장된다. 이 파라미터는 아카이브 로그 파일을 특정 경로에 백업하거나, 저장 위치를 관리하는 데 유용한다.
● LOG_ARCHIVE_DEST_STATE_n
LOG_ARCHIVE_DEST_STATE_n는 LOG_ARCHIVE_DEST에 지정된 디렉토리의 사용 여부를 결정한다. 사용 가능한 옵션은 다음과 같다:
- ENABLE: 기본값으로, 해당 경로를 사용함을 의미한다.
- DEFER: 정의된 경로 및 값들은 유지되지만 보류 상태가 된다.
- ALTERNATE: 다른 경로들이 실패할 경우 이 경로가 활성화된다.
● NLS_LANGUAGE
NLS_LANGUAGE는 데이터베이스에서 기본적으로 사용할 언어 설정을 지정한다. 이 파라미터는 날짜 형식(NLS_DATE_LANGUAGE)과 정렬 방식(NLS_SORT) 등 다양한 NLS 설정의 기본값에 영향을 준다.
● NLS_TERRITORY
NLS_TERRITORY는 언어와 날짜 형식을 설정하는 지역을 지정한다. 날짜 형식, 소수점 문자, 그룹 구분 기호, 지역 통화 기호 등의 기본값을 설정하는 데 사용된다.
● OPEN_CURSORS
OPEN_CURSORS는 한 세션당 최대 열 수 있는 CURSOR 개수를 설정하는 파라미터이다. 이 파라미터는 세션당 너무 많은 메모리를 사용하지 않도록 제한하는 데 유용한다. 기본값으로 권장되는 설정은 사용 패턴에 따라 조정해야 한다.
● PGA_AGGREGATE_TARGET
PGA_AGGREGATE_TARGET는 인스턴스에 접속한 전체 서버 프로세스가 사용할 수 있는 PGA(Program Global Area)의 총 크기를 결정한다. 이 값을 0보다 크게 설정하면, WORKAREA_SIZE_POLICY가 자동(AUTO)으로 설정되어 PGA 크기를 오라클이 자동으로 조절한다. 기본값은 SGA의 20%와 10MB 중 큰 값으로 설정된다.
● PROCESSES
PROCESSES는 오라클 관련 프로세스의 최대 개수를 설정하는 파라미터이다. 이 파라미터에는 사용자 프로세스와 백그라운드 프로세스를 포함한 모든 오라클 프로세스가 포함된다.
이 값이 부족하게 설정되면 서버에 접속이 불가능해질 수 있다. 기본값은 150개로 설정되어 있으며, 이 값을 변경할 때는 충분한 검토 후 수행하는 것이 좋다. 이 파라미터를 기준으로 SESSIONS와 TRANSACTIONS 파라미터의 기본값도 설정된다.
● RECYCLEBIN
RECYCLEBIN 파라미터는 10g 버전부터 추가된 휴지통 기능의 사용 여부를 지정한다. 기본값은 ON으로 설정되어 있으며, 이 경우 TABLE DROP 시 테이블이 휴지통으로 이동된다. 그러나 이 값을 OFF로 변경하면 삭제된 테이블은 즉시 영구 삭제된다. 이
● REMOTE_LISTENER
REMOTE_LISTENER 파라미터는 원격 리스너의 위치를 지정하는 파라미터이다. 이 위치는 원격 서버에 접속할 때 필요한 리스너 주소를 나타내며, 주로 tnsnames.ora 파일에 정의되어 있다.
● REMOTE_LOGIN_PASSWORDFILE
REMOTE_LOGIN_PASSWORDFILE 파라미터는 암호 파일을 사용해 원격에서 데이터베이스에 접속할 때 암호 파일의 사용 여부를 설정한다. 이 파라미터는 다음 세 가지 값을 가질 수 있다:
- SHARED: 여러 데이터베이스에서 하나의 암호 파일을 공유해서 사용할 수 있다. 암호 파일에는 SYS 유저와 Non-SYS 유저를 포함할 수 있다.
- EXCLUSIVE: 하나의 암호 파일은 한 개의 데이터베이스만 사용할 수 있다. 이 경우에도 암호 파일에는 SYS 및 Non-SYS 유저가 포함된다.
- NONE: 암호 파일을 사용하지 않으며, 오직 OS 인증 방식만을 사용한다.
이 파라미터가 SHARED 또는 EXCLUSIVE로 설정되더라도 암호 파일이 없을 경우에는 NONE 설정과 동일하게 동작하게 된다.
RESULT_CACHE 관련 파라미터
● RESULT_CACHE_MAX_RESULT (11g부터 사용 가능)
RESULT_CACHE_MAX_RESULT 파라미터는 RESULT CACHE 내에 저장되는 결과 중 하나의 결과가 사용할 수 있는 최대 크기를 지정하는 파라미터이다. 기본값은 RESULT_CACHE_MAX_SIZE의 5%로 설정되어 있다.
● RESULT_CACHE_MAX_SIZE (11g부터 사용 가능)
RESULT_CACHE_MAX_SIZE 파라미터는 RESULT CACHE의 총 크기를 설정하는 파라미터이다. 기본값은 Shared pool size, sga_target, memory_target에 따라 결정되며, 권장되는 비율은 다음과 같다:
- Shared Pool Size의 1%
- SGA Target의 0.5%
- Memory Target의 0.25%
● RESULT_CACHE_MODE (11g부터 사용 가능)
RESULT_CACHE_MODE 파라미터는 RESULT CACHE를 어떻게 운영할 것인지를 결정하는 파라미터로, 기본값은 MANUAL이다. 각 모드의 동작 방식은 다음과 같다:
- MANUAL: /*+ result_cache*/ 힌트를 사용한 쿼리에 대해서만 RESULT CACHE에 등록된다.
- FORCE: 모든 SQL 쿼리에 대해 RESULT CACHE에 등록되며, /*+ no result_cache*/ 힌트를 사용하는 쿼리는 RESULT CACHE에 등록되지 않는다.
- AUTO: MANUAL 모드보다 한 단계 더 발전된 모드로, Oracle이 내부적으로 많이 사용되는 쿼리 및 성능 향상을 위한 범위를 넘는 쿼리에 대해 RESULT CACHE에 자동으로 등록한다.
자동 모드와 관련된 히든 파라미터들은 다음과 같다:
- result_cache_auto_size_threshold: RESULT CACHE의 자동 크기 임계값
- result_cache_auto_max_size_allowed: RESULT CACHE의 자동 최대 크기 허용값
- result_cache_auto_time_threshold: 자동 시간 임계값
- result_cache_auto_execution_threshold: 자동 실행 임계값
- result_cache_auto_time_distance: 자동 시간 거리
SESSIONS 및 관련 파라미터
● SESSIONS
SESSIONS 파라미터는 오라클 서버에서 생성할 수 있는 최대 세션 수를 정의하는 파라미터이다. 이 파라미터는 최대 동시 접속자 수를 지정하며, 계산식은 다음과 같다:
(전체 동시 접속 인원 수 + 백그라운드 프로세스 수)×10%\text{(전체 동시 접속 인원 수 + 백그라운드 프로세스 수)} \times 10\%
이 파라미터는 ENQUEUE_RESOURCES와 TRANSACTIONS 파라미터의 값에 의해 결정되므로, SESSIONS 값을 변경할 경우 ENQUEUE_RESOURCES와 TRANSACTIONS 값도 조정해야 한다.
● SESSION_CACHED_CURSORS
SESSION_CACHED_CURSORS 파라미터는 한 세션 내에서 세 번 이상 사용된 커서를 캐시하는 개수를 지정하는 파라미터이다. 이 파라미터는 자주 사용되는 SQL 문장이 반복적으로 수행될 때 Library Cache Latch의 경쟁을 줄여 성능을 향상시키는 데 도움이 된다.
- Library Cache: SQL 문장과 실행 계획을 공유하는 장소로, 여러 서버 프로세스가 동시에 접근할 수 있다.
- 커서를 세 번 이상 사용하면, Oracle은 해당 커서를 PGA(Program Global Area)에 복사하여 재사용할 수 있도록 설정한다. 이로 인해 매번 Library Cache를 참조하는 대신 PGA에서 직접 찾을 수 있어 성능 향상 효과가 있다.
세션이 종료되더라도 LRU(Least Recently Used) 알고리즘에 의해 최신 커서에 자리를 양보하기 전까지 캐시된 커서는 유지된다.
● SESSION_MAX_OPEN_FILES
SESSION_MAX_OPEN_FILES 파라미터는 한 세션에서 열 수 있는 최대 BFILE의 개수를 지정한다. BFILE은 외부 파일을 참조할 수 있는 특수한 데이터 유형이다.
● SGA_TARGET
SGA_TARGET은 10g 버전부터 도입된 파라미터로, 자동 공유 메모리 튜닝 기능(Automatic Shared Memory Management: ASMM)을 사용하여 SGA의 전체 크기를 지정하는 파라미터이다. 이 파라미터를 설정하면 아래의 값들이 자동으로 튜닝 대상이 된다:
- Buffer Cache (DB_CACHE_SIZE)
- Shared Pool (SHARED_POOL_SIZE)
- Large Pool (LARGE_POOL_SIZE)
- Java Pool (JAVA_POOL_SIZE)
- Streams Pool (STREAMS_POOL_SIZE)
위의 다섯 가지 파라미터는 기본적으로 0으로 설정되어 있으며, 특정 값을 설정할 경우 최소값으로 인식되어 사용된다.
이러한 파라미터들은 오라클 데이터베이스의 성능과 안정성을 유지하는 데 중요한 역할을 하며, 설정 시 주의 깊은 조정이 필요하다.
Log Buffer 및 주요 파라미터
● Log Buffer
Log Buffer는 데이터베이스에서 발생하는 트랜잭션 로그를 임시로 저장하는 메모리 영역이다. 로그 버퍼는 데이터베이스의 안정성을 높이고, 로그 파일에 대한 쓰기 작업을 최적화하는 데 중요한 역할을 한다. 이 공간의 크기를 적절하게 설정하면, 트랜잭션 수행 시 I/O 성능을 향상시킬 수 있다.
● UNDO_TABLESPACE
UNDO_TABLESPACE는 Undo 데이터 저장을 위한 테이블스페이스를 지정하는 파라미터이다. 이 테이블스페이스는 트랜잭션의 롤백과 복구를 위한 Undo 정보를 저장하는 데 사용된다. Undo 관리 방식에 따라 UNDO_TABLESPACE의 성격과 용도가 달라질 수 있다.
● UNDO_MANAGEMENT
UNDO_MANAGEMENT 파라미터는 Undo 데이터의 관리 방법을 지정한다. 이 파라미터는 주로 두 가지 값으로 설정할 수 있다:
- AUTO: Oracle 서버가 자동으로 Undo를 관리하도록 설정한다. 이 모드는 Oracle 9i 버전부터 지원되며, 기본적으로 이 방식으로 운영된다.
- MANUAL: 사용자가 직접 Undo를 관리하는 방법으로 설정한다. 주로 장애가 발생한 경우 수동으로 관리해야 할 때 사용되며, 기본적으로는 자동 관리 모드를 사용하지만, 특정 상황에서 수동 관리를 필요로 할 수 있다. 이 파라미터는 관련된 테이블스페이스와의 연관성도 있으므로, 설정 시 주의가 필요한다.
● USER_DUMP_DEST
USER_DUMP_DEST는 사용자가 생성하는 트레이스 파일을 저장할 경로를 지정하는 파라미터이다. 사용자가 필요에 의해 생성하는 트레이스 파일의 기본 저장 경로로, 데이터베이스 성능 분석이나 문제 해결을 위해 트레이스 파일을 생성할 경우 이 경로를 통해 저장된다. 이 파일은 DBA와 개발자가 데이터베이스의 상태를 진단하고 문제를 해결하는 데 유용하다.
10g 설치 후 변경해야 하는 파라미터들
DG_BROKER_SERVICE_NAMES
- 설명: Data Guard 기능을 사용할 경우, 자동으로 등록되는 Service 이름을 설정한다. Data Guard를 사용하지 않을 경우, 이 파라미터를 비워서 Listener에 불필요한 Service가 등록되지 않도록 해야 한다.
- 설정 방법:
DG_BROKER_SERVICE_NAMES = ''B_TREE_BITMAP_PLANS
- 설명: SQL 실행 시 옵티마이저가 B-tree 인덱스를 Bitmap 인덱스로 변환하여 실행 계획을 수립하는 기능을 비활성화한다. 이 기능이 활성화된 경우 성능이 저하될 수 있으므로, FALSE로 설정하는 것이 좋다.
- 설정 방법:
B_TREE_BITMAP_PLANS = FALSEBLOOM_FILTER_ENABLED
- 설명: Bloom Filter는 대량의 데이터 중에서 특정 데이터의 존재 여부를 빠르게 찾는 기능이다. 대량의 데이터를 조인하거나 파티셔닝된 데이터를 처리할 때 이 기능이 사용될 수 있다. 그러나 성능 저하를 초래할 수 있는 경우가 있으므로, 이 기능을 비활성화하는 것이 좋다.
- 설정 방법:
BLOOM_FILTER_ENABLED = FALSECURSOR_SHARING
- 설명: SQL 커서 공유를 위한 설정으로, 이를 통해 메모리 사용을 최적화하고 성능을 향상시킬 수 있다. 일반적으로 FORCE로 설정하는 것이 좋다.
- 설정 방법:
CURSOR_SHARING = FORCEQUERY_REWRITE_ENABLED
- 설명: 쿼리 리라이트 기능을 활성화하여 쿼리 성능을 최적화한다. 이 기능은 리라이트가 가능한 뷰에 대해 성능을 개선할 수 있다.
- 설정 방법:
QUERY_REWRITE_ENABLED = TRUEENABLE_SECURITY
- 설명: 데이터베이스 보안을 강화하기 위한 설정이다. 이 값을 TRUE로 설정하면 보안 기능이 활성화된다.
- 설정 방법:
ENABLE_SECURITY = TRUEFAST_START_MTTR_TARGET
- 설명: 장애 발생 시 데이터베이스 복구 시간 목표를 설정하는 파라미터이다. 적절한 값으로 설정하여 데이터베이스의 가용성을 향상시킬 수 있다.
- 설정 방법:
FAST_START_MTTR_TARGET = 300설정 시 유의사항
- 각 파라미터의 변경은 데이터베이스의 성능에 큰 영향을 미칠 수 있다. 따라서 변경 후 충분한 테스트를 수행해야 한다.
- 파라미터 변경은 관리 문서화 및 백업 후 진행해야 하며, 변경 결과를 모니터링하여 성능 변화를 분석하는 것이 중요한다.
- 환경 및 사용 사례에 따라 최적의 설정이 달라질 수 있으므로, 다양한 테스트를 통해 적절한 값을 찾는 것이 좋다.
CLEANUP_ROLLBACK_ENTRIES
- 설명: 이 파라미터는 강제로 종료된 세션이 롤백을 수행할 때 SMON 프로세스가 한 번에 롤백할 수 있는 엔트리의 수를 설정한다. 값이 너무 높으면 롤백 처리 속도가 느려질 수 있다.
- 설정 방법:
CLEANUP_ROLLBACK_ENTRIES = 2000CLOSE_CACHED_OPEN_CURSORS
- 설명: 이 파라미터는 사용되지 않는 커서를 자동으로 닫도록 설정한다. 커서가 닫히지 않으면 메모리 낭비가 발생할 수 있으며, 이는 성능 저하를 초래할 수 있다. TRUE로 설정하면 사용되지 않는 커서를 자동으로 닫다. 다만, 현재 커서를 사용 중인 프로그램이 있을 경우, FALSE로 설정하는 것이 더 안전할 수 있다.
- 설정 방법:
CLOSE_CACHED_OPEN_CURSORS = TRUECOMPLEX_VIEW_MERGING
- 설명: 옵티마이저가 쿼리 실행 시 복잡한 뷰를 병합하는 기능을 설정한다. 이 기능은 성능 향상에 긍정적인 영향을 미칠 수 있지만, 경우에 따라 비효율적일 수 있다. 성능 테스트를 통해 사용 여부를 결정해야 한다.
- 설정 방법:
COMPLEX_VIEW_MERGING = FALSEOPTIMIZER_MODE
- 설명: 옵티마이저의 모드를 설정한다. 일반적으로 ALL_ROWS 또는 FIRST_ROWS로 설정하여 성능을 조절할 수 있다.
- 설정 방법:
OPTIMIZER_MODE = ALL_ROWS
- CURSOR_FEATURES_ENABLED
- 설명: 특정 세션에서 함수 수행 시 발생하는 kks-fbc child completion 대기 상태와 관련된 버그를 해결하기 위해 사용되는 파라미터이다. 이 파라미터는 특정 버그 해결을 위한 패치가 적용된 후 활성화해야 한다.
- 설정 방법:
CURSOR_FEATURES_ENABLED = 10
- FAST_START_INSTANCE_RECOVERY_TARGET
- 설명: RAC(Real Application Clusters) 환경에서 하나의 노드가 장애로 중단되었을 때, 나머지 노드에서 해당 인스턴스를 복구하는 데 소요되는 최대 시간을 설정한다. 이 값을 적절히 조정하면 장애 복구 시간이 단축될 수 있다.
- 설정 방법:
FAST_START_INSTANCE_RECOVERY_TARGET = 360
- GBY_HASH_AGGREGATION_ENABLED
- 설명: 10g R2 버전부터 GROUP BY 연산 시 해시 알고리즘을 사용하여 성능이 향상되었다. 그러나 결과값이 정렬되지 않기 때문에, 정렬된 결과가 필요할 경우 ORDER BY 구문을 별도로 추가해야 한다. 성능 개선을 위해 기본값은 TRUE로 설정되어 있다.
- 설정 방법:
GBY_HASH_AGGREGATION_ENABLED = FALSE- GC_AFFINITY_TIME
- 설명: 요청한 데이터에 대한 마스터 노드를 조사하는 데 소요되는 시간을 설정하는 파라미터이다. 주서버가 위치한 노드에서 데이터를 받아 사용자에게 반환해야 하며, 이 파라미터는 동적 리마스터링을 위해 설정된다. , 값을 18로 설정하면 18초마다 리마스터링을 시도한다.
- 주의사항: RAC 환경이 아닐 경우 이 값을 0으로 설정하면 리마스터링을 하지 않도록 할 수 있다. RAC 환경에서는 기본값이 16분으로 설정되어 있다.
- GC_UNDO_AFFINITY
- 설명: RAC에서 Undo Segment를 활성화한 노드가 자동으로 마스터 노드로 변경되지 않도록 설정하는 파라미터이다. 이 값을 FALSE로 설정하는 것이 권장된다.
- IN_MEMORY_UNDO
- 설명: In-Memory Undo 기능이 활성화되면 Undo 데이터가 Undo Segment에 기록되지 않고 Shared Pool에 미리 만들어진 IMU Pool에 기록된다. IMU Pool이 가득 차면, 기록된 데이터를 한꺼번에 Undo Segment에 저장하고 이후의 Undo 데이터는 다시 Undo Segment에 기록하게 된다. 이 기능은 작은 트랜잭션의 경우 성능을 개선하기 위해 도입되었다.
- 장점: 작은 트랜잭션이 많은 경우 성능 향상에 유리한다.
- 단점: 대량의 데이터가 변경되는 경우 성능 저하를 유발할 수 있다. 따라서 사용 여부는 신중하게 판단해야 한다.
- KKS_USE_MUTEX_PIN
- 설명: Oracle 10g부터 Shared Cursor를 관리하기 위해 Mutex를 사용하는 기능이 도입되었다. 기본값은 사용으로 설정되어 있으나, 이 기능이 기존의 Lock/Latch 방식보다 성능이 좋지 않은 경우가 많다.
- 권장 설정: 성능 저하를 방지하기 위해 이 기능을 비활성화하는 것이 좋다. 값을 FALSE로 설정한다.
- OPTIM_PEEK_USER_BINDS
- 설명: Bind Peeking 기능의 사용 여부를 결정하는 파라미터이다. Bind Peeking은 옵티마이저가 실행 계획을 세울 때 사용되지만, 부작용이 많아 사용하지 않는 것이 권장된다.
- Bind Peeking의 예: 사용자가 서점에서 특정 책을 조회할 때, 100권의 책 중 99권이 A라는 책이고 1권이 B라는 책인 경우, 옵티마이저는 이 정보를 기반으로 실행 계획을 세우게 된다.
- 권장 설정: Bind Peeking을 비활성화하여 부작용을 방지한다.
Bind Peeking 및 Adaptive Cursor Sharing
- Bind Peeking
- 문제점: Bind Peeking 기능은 옵티마이저가 실행 계획을 세울 때 사용자로부터 입력받은 값을 기반으로 한다. , A라는 책이 99권이고 B라는 책이 1권 있는 경우, 사용자가 A를 조회하면 최적의 실행 계획이 세워지지만, B를 조회할 경우 성능이 저하된다.
- 실행 계획 설정: 사용자가 입력하는 값에 따라 옵티마이저는 예상할 수 없는 상태에서 실행 계획을 수립하게 된다. 이로 인해 데이터의 양은 많지만 종류가 A와 B 두 가지뿐이므로, 옵티마이저는 전체 스캔(FULL SCAN)을 선택하게 된다. 이러한 설정은 성능 저하의 원인이 된다.
- 권장 설정: Bind Peeking 기능은 비활성화하는 것이 좋다.
- Adaptive Cursor Sharing (ACS)
- 설명: Oracle 11g에서 도입된 이 기능은 사용자가 입력하는 값마다 별도의 실행 계획을 수립하여 성능을 개선한다. 즉, 사용자가 A를 입력하면 A에 맞는 실행 계획을 생성하고, B를 입력할 경우 A의 계획으로 실행해보고 성능이 좋지 않으면 B에 대한 새로운 계획을 수립한다.
- 장점: Bind Peeking의 문제를 일부 해결하지만, A로 실행한 후 성능이 좋지 않을 경우 B를 다시 수행해야 하므로 성능 저하의 가능성이 여전히 존재한다.
- 권장 설정: Oracle 10g를 사용할 경우 Bind Peeking 기능이 기본적으로 활성화되어 있으므로, 이를 비활성화하는 것이 좋다.
Oracle Optimizer Parameters
- OPTIMIZER COST BASED TRANSFORMATION - OFF
- Oracle 옵티마이저는 SQL 문에서 View나 Sub-Query를 만나면 실행 계획을 세우기 전에 항상 변환 작업을 수행한다. 이 과정을 Query Transformation이라고 하며, 9i까지는 항상 Rule Base로 진행되었다. 16g 이상의 버전에서는 Cost Base로 변환 작업을 수행하게 된다.
- 9i에서 잘 작동하던 변환 작업이 10g 이후에 정상적으로 이루어지지 않을 수 있으므로, 이 파라미터를 OFF로 설정해 사용할 수 있다.
- OPTIMIZER PUSH PRED COST_BASED - FALSE
- 9i 버전의 옵티마이저에서 정상적으로 Push Predicate이 이루어지는 쿼리가 10g에서는 발생하지 않는 경우가 있다. 일반적으로 통계 정보가 정확하다면 최적의 판단이 이루어지지만, 특정 쿼리에서는 Push Predicate이 발생하지 않아 비효율적인 실행 계획이 수립될 수 있다.
- 이러한 경우, OPTIMIZER_PUSH_PRED_COST_BASED 파라미터 값을 FALSE로 변경하여 9i 버전과 같이 Rule Base 기반에서 쿼리 변환이 이루어지도록 설정해야 한다.
- PX_USE_LARGE POOL - TRUE
- Parallel Query를 수행할 경우 Large Pool 사용 여부를 결정하는 파라미터이다. TRUE로 설정하는 것을 권장한다.
- ROW CACHE_CURSORS - 1000
- 데이터 사전 캐시에 캐싱되는 양을 지정한다. 기본값은 20인데, 이 값이 너무 작으므로 충분히 크게 설정하는 것을 권장한다.
추가 사항
- 위에서 언급한 18가지의 파라미터들은 데이터베이스 생성 후에 추가로 변경하는 것을 권장한다. 이러한 설정들은 데이터베이스의 성능을 최적화하는 데 중요한 역할을 한다.
11g 설치 후 변경해야 하는 파라미터
- OPEN LINKS
- 하나의 세션에서 동시에 사용할 수 있는 데이터베이스 링크의 개수를 지정하는 파라미터이다. 초기값은 4개로 설정되어 있는데, 이 개수가 부족할 수 있으므로 충분히 많은 값으로 지정하는 것이 좋다 (예: 40개).
- OPEN LINKS PER INSTANCE
- 하나의 인스턴스에서 동시에 사용할 수 있는 데이터베이스 링크의 개수를 지정하는 파라미터이다. 초기값이 4개로 설정되어 있으며, 필요에 따라 충분히 많은 값으로 조정하는 것이 권장된다 (예: 4개).
- MEMORY_TARGET
- 11g 버전부터 등장한 메모리(SGA + PGA) 크기를 자동으로 튜닝해주는 기능을 사용할 때 메모리 양을 지정하는 파라미터이다. 초기값은 166으로 설정되어 있으나, 이 파라미터의 크기를 0으로 주거나 앞부분에 # 처리하여 주석 처리하는 것을 권장한다.
- 좋은 기능처럼 보이지만, 이 파라미터 사용으로 인해 여러 가지 부작용이 발생할 수 있으므로, 사용 여부는 충분히 테스트한 후 결정하는 것이 좋다.
- DB WRITER PROCESSES
- DBWR 프로세스의 기본 개수를 지정하는 파라미터로, 기본값은 1이지만 2로 변경하는 것을 권장한다.
- SESSION CACHED CURSORS
- 하나의 세션당 캐싱되는 커서의 개수를 지정하는 파라미터이다. 기본값은 50인데, 충분히 큰 값(예: 500)으로 지정하는 것이 좋다.
- DIAG DAEMON
- 분석 데몬의 자동 시작 여부를 결정하는 파라미터이다. 기본값은 TRUE인데, FALSE로 변경하는 것을 권장한다.
Oracle 데이터베이스 시작 단계 및 관련 파일
- 시작 단계
- Oracle 데이터베이스를 시작하는 과정은 총 3단계로 구성되어 있다: NOMOUNT, MOUNT, OPEN. 각 단계에서 필요한 파일과 수행되는 작업은 다음과 같다.
- NOMOUNT 단계
- 이 단계에서는 Parameter File(파라미터 파일)만 사용된다. 이때 데이터베이스 인스턴스는 시작되지만, 데이터베이스는 아직 Mount되지 않다.
- NOMOUNT 단계에서는 Parameter File이 사용 중이라고 간주된다.
- MOUNT 단계
- 이 단계에서는 Parameter File과 Control File이 사용된다. 데이터베이스가 Mount되어 데이터베이스 파일에 대한 정보가 필요한다.
- 이 시점에서 Data File과 Redo Log File은 사용되지 않으며, 필요에 따라 Data File을 재배치할 수 있다. 재배치가 필요할 경우, 해당 Data File을 사용하지 않도록 설정하거나 데이터베이스를 종료한 후 Mount만 수행하여 작업을 진행해야 한다.
- OPEN 단계
- 이 단계에서는 모든 데이터 파일과 Redo Log File이 사용되며, 데이터베이스가 정상적으로 운영 상태로 전환된다.
- NOMOUNT에서 MOUNT를 건너뛰고 OPEN으로 직접 갈 수는 없다. 반드시 NOMOUNT - MOUNT - OPEN의 순서로 진행해야 한다.
- ALTER DATABASE 명령어
- 원하는 단계까지 시작한 후, 작업을 마치고 나머지 단계를 진행하려면 ALTER DATABASE 명령어를 사용한다. 예시로는 다음과 같은 명령어가 있다:
SYS> STARTUP NOMOUNT; SYS> ALTER DATABASE MOUNT; SYS> ALTER DATABASE OPEN;
- 원하는 단계까지 시작한 후, 작업을 마치고 나머지 단계를 진행하려면 ALTER DATABASE 명령어를 사용한다. 예시로는 다음과 같은 명령어가 있다:
- 주의사항
- 사용 중인 파일이란 데이터베이스가 해당 파일을 읽거나 쓸 때 사용되고 있다는 의미이다. 사용 중인 파일은 복사하거나 삭제할 수 없으므로, 적절한 조치를 취해야 한다.
- 데이터 파일이나 Redo Log 파일을 재배치해야 할 경우, 해당 파일이 사용되지 않도록 설정하거나 데이터베이스를 종료 후 MOUNT 단계만 실행하여 재배치를 수행하는 것이 중요한다.
MOUNT 단계 후 진행 방법
- MOUNT 단계로 시작하기
- 인스턴스를 MOUNT 상태로 시작한다:
- MOUNT 상태에서는 데이터베이스가 시작되었지만, 아직 OPEN되지 않은 상태이다.
- 인스턴스를 MOUNT 상태로 시작한다:
- READ ONLY 모드로 OPEN하기
- 데이터베이스를 읽기 전용 상태로 OPEN하려면 아래 명령어를 사용한다:
SYS> ALTER DATABASE OPEN READ ONLY; - 읽기 전용 모드에서는 SELECT 외의 모든 데이터 변경 작업이 불가능하다. 이 모드는 주로 감사 작업 등 데이터 변경을 방지하면서 조회만 수행해야 할 경우 유용하다.
- 만약 읽기 전용 모드에서 다시 데이터 변경이 가능한 상태로 변경하려면, 인스턴스를 종료하고 정상적으로 시작해야 한다.
- 데이터베이스를 읽기 전용 상태로 OPEN하려면 아래 명령어를 사용한다:
- Restricted Mode로 OPEN하기
- 데이터 변경은 가능하지만, 허가된 사용자만 접속할 수 있는 Restricted Mode로 OPEN할 수 있다. 이 모드는 주로 유지 관리 작업을 수행할 때 유용한다.
- Restricted Mode로 시작하려면 다음 명령어를 사용한다:
SYS> STARTUP RESTRICT; - 현재 OPEN되어 있는 인스턴스를 Restricted Mode로 변경하려면 다음 명령어를 사용한다:
SYS> ALTER SYSTEM ENABLE RESTRICTED SESSION; -- 제한된 세션 활성화 SYS> ALTER SYSTEM DISABLE RESTRICTED SESSION; -- 제한된 세션 비활성화 - Restricted Mode로 OPEN된 인스턴스에 접속하려면 Restricted Session 권한이 있어야 한다.
- MOUNT 단계 후 OPEN 단계로의 전환 방법은 여러 가지가 있으며, 각각의 모드(READ ONLY, RESTRICTED)의 사용 목적에 따라 다르게 설정할 수 있다.
Oracle Instance 종료하기
Oracle 인스턴스를 종료하는 명령어는 SHUTDOWN이다. 이 명령어를 실행하기 위해서는 DBA 권한이 필요한데, 보통 SYS 사용자로 로그인하여 작업을 수행한다. 아래는 인스턴스를 종료하는 기본적인 방법이다:
sqlplus sys/oracle as sysdba
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.Shutdown의 4가지 옵션
- NORMAL (기본 옵션)
-
SYS> SHUTDOWN NORMAL; - 이 옵션은 현재 연결된 모든 사용자가 스스로 세션을 종료할 때까지 기다린다. 만약 어떤 사용자도 세션을 종료하지 않으면, 인스턴스는 종료되지 않는다. 이 방식은 데이터의 무결성을 유지할 수 있지만, 시간이 오래 걸릴 수 있다.
-
- IMMEDIATE
- 사용법:
SYS> SHUTDOWN IMMEDIATE; - 이 옵션은 현재 연결된 사용자에게 즉시 세션 종료를 요청하고, 모든 활동 중인 트랜잭션을 롤백한 후 즉시 인스턴스를 종료한다. 사용자가 기다리지 않기 때문에 빠르게 종료할 수 있다.
- 사용자의 동작에 관계없이 즉시 접속을 강제 종료한다. 사용자가 수행한 작업 중 COMMIT이 완료된 데이터는 데이터 파일로 저장되고, COMMIT이 완료되지 않은 작업은 ROLLBACK된다. 이후 정상적으로 인스턴스가 종료된다.
- 사용법:
- TRANSACTIONAL
- 사용법:
SYS> SHUTDOWN TRANSACTIONAL; - 이 옵션은 현재 진행 중인 트랜잭션이 완료될 때까지 기다리고, 이후 연결된 모든 사용자가 세션을 종료하면 인스턴스를 종료한다. 사용자가 트랜잭션을 완료하는 것을 보장하지만, 사용자 세션은 종료할 때까지 기다려야 한다.
- 현재 사용자가 실행 중인 트랜잭션이 끝날 때까지 기다린 후 인스턴스를 종료한다. 사용자가 DML 작업을 수행 중일 경우, 해당 트랜잭션을 종료하는 명령을 수행하면 인스턴스가 종료된다. 사용자가 트랜잭션을 종료하지 않으면 인스턴스는 종료되지 않다.
- 사용법:
- ABORT
-
SYS> SHUTDOWN ABORT; - 이 옵션은 인스턴스를 강제로 종료한다. 현재 진행 중인 트랜잭션이 롤백되며, 이 방법은 데이터 무결성을 보장하지 않으므로 일반적으로 마지막 수단으로 사용된다.
- 즉시 접속을 강제 종료하지만, 사용자가 수행한 작업을 저장하거나 ROLLBACK하지 않고 바로 인스턴스를 종료한다. 이는 서버 전원이 꺼진 것과 같은 비정상 종료를 의미하며, 인스턴스가 다시 시작될 때 SMON 프로세스가 복구를 수행해야 한다. 이 옵션은 치명적인 위험을 줄 수 있으므로 매우 주의해야 한다.
-
'DBMS > ORACLE Admin' 카테고리의 다른 글
| 언두 데이터의 읽기 일관성 (0) | 2025.01.11 |
|---|---|
| 오라클 사용법 (0) | 2025.01.11 |
| 오라클 관리 04 ORACLE Net Service (0) | 2024.10.27 |
| 오라클 관리 03 DBMS_JOB, DBMS_SCHEDULER (0) | 2024.10.25 |
| 오라클 관리 02 사용자 (0) | 2024.10.24 |